
Senior technology leaders are under constant pressure to “do something with AI.” Boards want productivity gains. Vendors promise autonomous agents. Engineering teams are experimenting with coding copilots, browser agents, code-review bots, test-generation tools, and multi-agent orchestration systems.
The sales narrative is dangerously simple: connect a powerful model to tools, give it a goal, let one agent write the work and another review it, and watch delivery accelerate.
The evidence, however, is not that simple.
Generative AI is useful. It can accelerate parts of software development, writing, research, analysis, testing, documentation, and support. In bounded environments, it can perform well. But it remains far from reliable autonomous end-to-end execution.
TL;DR
- No independent evidence verifies that any GenAI model can execute complex tasks end-to-end with 100% accuracy and no human oversight.
- AI performs best in bounded workflows with clear inputs, explicit context, and external validation.
- Benchmark results show a sharp gap between constrained coding tasks and realistic autonomous web workflows.
- AI-assisted coding does not always save time; in mature codebases, it can slow experienced developers down.
- More AI-generated output can increase review burden, especially for senior engineers.
- Agentic review is not the same as independent verification; “AI checking AI” can create confident failure.
- Leaders should start with documentation, task decomposition, and success criteria before prompting.
- Treat AI as a high-leverage assistant inside a governed workflow, not as an autonomous operator.
Table of Contents
Download the AI Integration Playbook
AI integration is now a leadership challenge as much as a technical one.
It is not enough to run a few experiments, buy another AI tool, or ask teams to “find use cases.” Technology leaders need a way to decide what belongs in production, what needs stronger controls, what creates business value, and what introduces unnecessary risk.
The AI Integration Playbook for Technology Leaders gives you that structure.
If you are still working through the bigger question of how AI fits into your technology strategy, the related guide “Tech Leaders Guide to AI Integration” explains the full strategic context: infrastructure readiness, secure environments, business-aligned use cases, governance, compliance, cost control, and responsible innovation. This Playbook goes beyond that strategic explanation, straight into phased execution.
The Uncomfortable Reality
Here’s the harsh reality beyond marketing claims and hype: there is no single independent source that can verify that any model can execute any task end-to-end with 100% accuracy without human oversight or intervention. It simply does not exist.
(Our own usage that spans from deep research, intelligence, and analytics to software development, repos, and agent orchestration confirms that we cannot rely on AI end-to-end, even for the simplest of tasks.)
And the methodology of our research was simple: disregard any source that is in any way affiliated with anyone inside the sales chain of any model (from publisher to vendors to media/testing/benchmarking platforms funded by organizations directly or indirectly connected to companies behind Gen AI models). Turns out, the majority of “sources” and “independent benchmarks” are not independent at all, and that’s something you have to keep in mind when you are evaluating a model for possible inclusion in your stack, regardless of the use case. It should be the second step, right after defining a problem statement.
The Practical Conclusion
AI should be treated as an assistant inside a highly governed workflow, not as an accountable operator.
This distinction matters because many failed AI implementations begin with the wrong operating model. Teams treat the system as if it were a junior employee who can infer intent, understand organizational context, recover from ambiguity, and verify its own output.
In reality, even strong models behave more like powerful but inconsistent interfaces. They can produce useful work when the task is split into small chunks, well-bounded, the context is explicit, and the quality criteria are external to the model itself. In contrast, they become much less reliable when asked to run a messy process from start to finish.
Two Benchmark Families Illustrate the Gap
Aider’s Polyglot benchmark tests whether models can edit code successfully across 225 Exercism exercises in C++, Go, Java, JavaScript, Python, and Rust. The best listed configurations perform well: GPT-5 high at 88.0%, GPT-5 medium at 86.7%, o3-pro high at 84.9%, Gemini 2.5 Pro Preview at 83.1%, and GPT-5 low/o3 high at 81.3%. That makes the median of those top five scores of 84.9%.
That is a strong result, but it is not 100%, and, more importantly, it is achieved in a favorable environment: bounded coding tasks with files, tests, and pass/fail feedback. Consider this: What if in that remaining 15.1% that fail, you have guardrails, security, legal, privacy, and/or finances?
Even the top result still fails 27 out of 225 tasks.
Now compare that with WebArena, a benchmark designed to evaluate autonomous browser agents on realistic web tasks. WebArena includes self-hosted websites across domains such as e-commerce, forums, collaborative software development, content management, maps, calculators, scratchpads, and knowledge resources. The agent must navigate interfaces, interpret state, plan multiple steps, use tools, recover from mistakes, and decide when the task is complete.
In WebArena’s original results, the best GPT-4-based agent achieved only 14.41% end-to-end task success, while human performance reached 78.24%. Among the top five non-human configurations in the published results, the median score is 8.75%. If you’ve been a GPT-4 user who has now switched to 5.5, you know that the difference in performance between the older and new model is not significant.
The Contrast Is the Main Point
On a constrained coding task with executable feedback, models can appear highly capable. On realistic web workflows that require long-horizon action, contextual judgment, and error recovery, performance collapses. In other words, the gap between 84.9% and 8.75% is the gap between bounded assistance and operational autonomy.
The same pattern appears in coding productivity research
The assumption that AI-assisted coding is always faster is not supported by independent evidence. In a 2025 randomized controlled trial, METR studied 16 experienced open-source developers completing 246 tasks in mature repositories they knew well. Developers expected AI tools to reduce completion time by 24%. After using them, they believed the tools had saved about 20%. The measured result, however, went in the opposite direction: AI-assisted developers took 19% longer. The slowdown came from prompting, waiting, reviewing, and correcting output.
That does not mean AI coding tools never speed teams up. A separate controlled study of undergraduate students working on Brownfield programming tasks found that students completed tasks 35% faster with GitHub Copilot and made 50% more solution progress. They also spent less time manually writing code and less time searching the web. But the same study reported student concerns about not understanding how or why suggestions worked. And that’s the hidden danger in the long run.
The Implication Is Uncomfortable but Important
AI-assisted coding often helps less-experienced developers produce more code faster, especially in controlled or unfamiliar tasks. However, it may not help experienced developers move faster in complex repositories they already understand. In some settings, it can significantly slow them down.
There is also a maintenance-burden problem
A study of open-source development after Copilot adoption found that productivity gains were driven mainly by less-experienced contributors, while more experienced core developers had to review more code. The study reports that core developers reviewed 6.5% more code and experienced a 19% drop in original code productivity.
Tilburg University’s summary of the same research frames the issue directly: productivity gains may come at the expense of quality and sustainability, because senior developers absorb the hidden rework.
This is where the leadership risk becomes acute
AI can increase output volume before it increases verification capacity. If junior or peripheral contributors generate more code, and senior engineers must review more of it, the bottleneck does not disappear. It moves upstream into architecture, specification, integration, and review. The team may feel faster while becoming more fragile.
Former GitHub senior engineer Zen van Riel has warned about exactly this failure mode. In his video “I Quit My GitHub Job Because AI Breaks Software,” van Riel argues that companies are beginning to replace parts of the software development lifecycle with AI agents, including code review, testing, deployment decisions, and architecture. He acknowledges the productivity boost, but warns that unchecked agentic coding creates a mathematical certainty of bugs because developers cannot manually verify the growing volume of generated code. His central objection is not to AI assistance; it is to substituting autonomous systems for human oversight and then trusting AI to monitor other AI.
That warning aligns with what the benchmark and productivity evidence suggest. The problem is not that AI always writes bad code. The problem is that AI can produce more output than teams can understand, test, review, and maintain. Once that happens, the organization is no longer accelerating engineering. It is accumulating unverified complexity.
Axel Molist, CEO of Wu and leader of a 20-person software development team, describes the same shift from a management perspective. In “What 6 Months of AI Coding Did to My Dev Team,” Molist argues that AI has moved the primary workload from writing code to supervising and architecting systems. As tools generate code faster, the bottleneck moves upstream into precise technical specifications, documentation, architectural judgment, and institutional knowledge. Senior engineers become traffic controllers for machine-generated output, while junior developers may see immediate productivity gains without fully understanding the systems they are changing.
The Strategic Point Vendor Narratives Avoid
AI does not remove the need for engineering discipline. It just moves the engineering discipline earlier in the process.
Before AI, weak specifications often caused confusion during implementation. With AI, weak specifications cause plausible code to appear quickly. That makes the failure more dangerous because the system does not stop and say, “Hey, your requirements are incomplete.” It just fills in the gaps, predicting the next word or symbol. In other words, it invents assumptions and generates structure. It may even pass narrow tests while violating product intent, security expectations, architectural constraints, or operational realities.
Agent orchestration can make this worse
Things can go south really fast if leaders mistake orchestration for independent verification.
A second model reviewing the first model is still the same class of system: probabilistic, context-sensitive, and vulnerable to similar blind spots.
Granted, multi-agent review may improve coverage in some workflows, but it is not equivalent to independent validation. If the same missing context, bad assumption, or weak specification is present across agents, the review layer can simply produce a more confident failure.
This is why “AI reviewing AI” should not be the foundation of quality assurance. It can be one layer, but not the final authority.
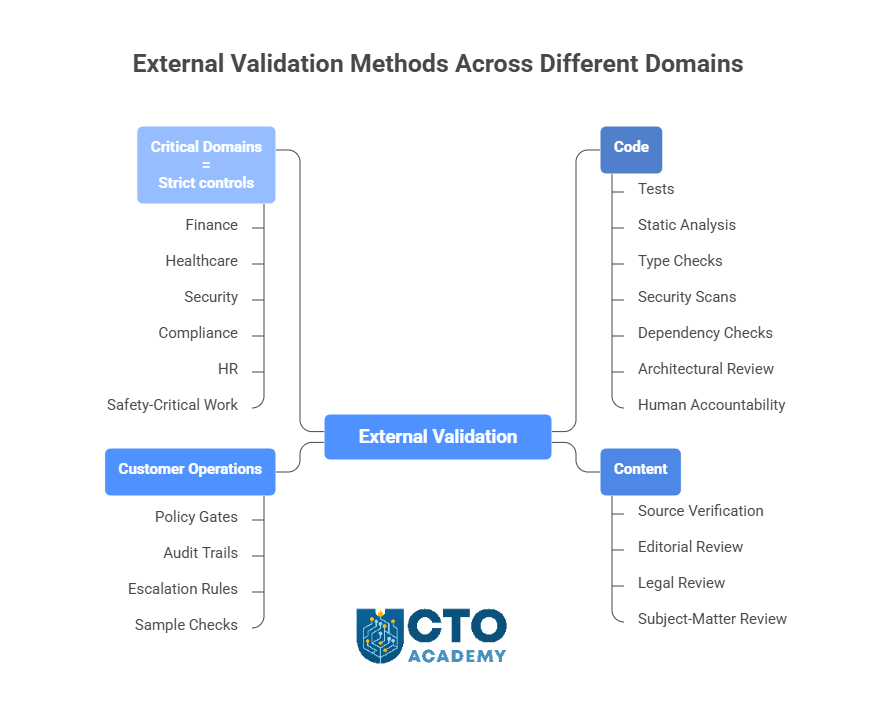
- For code, external validation means tests, static analysis, type checks, security scans, dependency checks, architectural review, and human accountability.
- For content, it means source verification, editorial review, legal review, or subject-matter review.
- For customer operations, it means policy gates, audit trails, escalation rules, and sample checks.
- For finance, healthcare, security, compliance, HR, or safety-critical work, it means strict controls designed around the consequences of failure.
The right operating model is therefore not “autonomous AI employee.” It is “high-leverage assistant embedded in a governed workflow.”
That model changes the implementation plan.
The Correct Implementation Sequence
Step 1: Document before prompting
- What is the exact task?
- What inputs are allowed?
- Which sources are authoritative and trusted?
- What assumptions are forbidden?
- What edge cases matter?
- What does a correct output look like?
- What must the system do when information is missing?
- What evidence must be attached?
- What decisions require immediate escalation?
A prompt without this surrounding documentation is not a process. It is an improvisation request.
Step 2: Decompose work into bounded tasks
AI is strongest when asked to assist with defined pieces of work. For example:
- Summarize this document.
- Propose tests for this function.
- Draft a migration plan using these constraints.
- Extract these fields from this contract.
- Compare these two policies.
- Generate a first-pass implementation for this ticket.
- Identify contradictions in this requirements document.
It is weaker when asked to “handle the process” without a precise operating frame.
Step 3: Measure delivery rather than output
Lines of code, number of commits, number of generated test cases, or number of tickets touched are weak measures. Leaders should instead measure:
- Time to accepted pull request
- Review cycles
- Rework rate
- Defect leakage
- Incident rate
- Senior-review load
- Maintainability
- The percentage of AI-generated work that is accepted without substantial modification.
Step 4: Protect senior engineers from becoming the hidden bottleneck
If AI increases code volume by 30%, but senior engineers spend 40% more time reviewing fragile output, the organization has not improved productivity. It has redistributed the cost.
Engineering leaders need explicit capacity planning for review, architectural governance, and documentation maintenance.
Step 5: Preserve institutional knowledge
As Molist argues, specifications increasingly become the product. If the AI can generate code quickly, then the durable asset is not the first draft of the implementation. It is the clarity of the system design, constraints, domain model, naming conventions, failure modes, operational rules, and business logic. Teams that fail to document these will become strangers to their own software.
He provided a vivid example. The company’s server crashed, returning the 503 error. An on-call junior developer used a proprietary AI to diagnose the problem and seek advice. The model read the documentation and suggested a reboot. The technician rebooted the instance, but it crashed again. So he again prompted the model. Repeated reading of the same documentation – as models commonly do — returned the same advice: reboot. He ended up rebooting the server 6 times, and it crashed every time. Until a senior developer checked the logs and immediately spotted the problem. As you can guess, some long-forgotten cron job hidden in one of the backend systems filled up the memory, causing the overload. The problem was that nobody remembered to include that specific cron job in the documentation, so the AI was completely unaware of it – just like the junior developer.
Conclusion
Generative AI will continue to improve. Agentic systems will become more capable. Some bounded tasks will probably reach very high reliability. But the evidence today does not support the claim that AI can execute complex end-to-end work with perfect accuracy and no human intervention.
The strongest results appear in constrained environments with clear feedback. The weakest results appear in realistic workflows with ambiguity, long-horizon planning, and high integration cost.
For senior technology leaders, the practical takeaways are clear:
- Deploy AI aggressively where the workflow is bounded, observable, and externally verifiable.
- Be cautious where the task requires judgment, tacit knowledge, compliance, safety, or accountability.
- Do not let vendor claims replace internal measurement.
- Do not let agentic review replace independent validation.
- Most importantly, start with documentation, not with prompts.
Contrary to bombastic claims, AI is not even remotely ready to be trusted as an autonomous operator – at any level. But it is well-equipped to be used as an assistant by teams disciplined enough to tell it exactly what good work looks like. From the CTO’s perspective, this means focusing on team leadership first and only then on technology management.



")


")
")



")

")
")
")




















