Technology leaders need AI judgment, not AI courses.
What we picked up in this last year or so is that many technology leaders are barking at the wrong tree, operating as developers rather than leaders. The pressure of AI integration is so high that they have forgotten what they’ve been paid for.
This is especially true for aspiring tech leaders who are now trying to figure out whether they should go strategic or more tactical. Unfortunately, they often choose the latter and end up with that familiar “Open-for-work” badge on their LinkedIn profile image.
AI-induced career uncertainty is causing anxiety, making many aspiring technology leaders less convinced that executive leadership development is the fastest route to career security. The irony is that the market still needs business-fluent technology leaders. Deloitte’s 2026 Global Technology Leadership Study describes a shift from technology leaders being judged by operational stability to being judged by enterprise-wide value, measurable business outcomes, and AI-enabled business impact.
80% of more than 600 US technology leaders say their roles and responsibilities have greatly expanded to meet business objectives.
During the tech boom, senior technologists could see a clear path upward: manager → head of engineering → VP engineering → CTO. Companies were hiring, teams were growing, and leadership education felt like an accelerator.
Now, the path feels less linear. Companies want fewer leaders, more business accountability, more AI leverage, better cost control, and faster evidence of impact. Senior engineers came to the impression that broad leadership development doesn’t matter anymore. Instead of pursuing leadership programs that actually prep them for the role, they are enrolling in developer programs.
There is nothing wrong with understanding certain aspects of new technologies, but if pushed too far, a person can lose sight of what matters.
Both deliver exactly what a technology leader needs. The former further strengthens the multidisciplinary skillset required to lead at an executive level. The latter provides a simple insight into the underlying principles of integration.
But…and this is a big but…the playbook is designed to assist leaders when they are pressured by CEOs and boards to implement or even switch core business assets to AI in any way they can. It doesn’t teach you where the implementation fits into broader business goals. It doesn’t show you where AI can improve operations, accelerate delivery, reduce risk, create new capabilities, and support measurable business outcomes.
That’s the part covered in the Digital MBA.
In other words, just because you know how to set up agentic orchestration or AI workflow, it doesn’t mean you should do it.
The following graphic best represents this statement:
Two logics of AI workflows and agentic orchestrations: business logic and technical logic. The former is a leader’s responsibility, while the latter is owned by developers.
If you are really manually setting up workflows and orchestrations, you are not leading; you are micromanaging. In other words, you are wasting everyone’s time and money.
This should be a responsibility of a junior developer who can do this at 4 am after an entire night out with eyes closed.
But the junior dev can’t do this unless you provide the blueprint.
That blueprint is the key because it answers two critical questions:
Why are we doing this (to what end)?
Is this only a solution looking for a problem?
Here’s an example:
“We should automate reporting.”
Why? Which part? For whom? What will we get out of it? It simply isn’t clear enough to guide the initiative. Nonetheless, that’s the most common request coming from the CEO or board.
And this is where a technology leader comes in. The job is to:
Identify the user.
Describe the friction.
Explain the costs in both time and money dimensions.
Define success.
Create a measurable test of that success.
As you can see, we are not even near the actual workflow or orchestration design.
The Critical Problem
Most aspiring technology leaders are not short of AI awareness. They are short of translation ability.
In other words, they can see the tool, the demo, and how quickly a workflow can be assembled. But they cannot always translate that into a business case strong enough to survive scrutiny from the CEO, CFO, board, customers, legal, security, operations, and the team that has to maintain it six months later.
That is not an AI problem.
That is a leadership problem.
And it is exactly why a dedicated AI course can be the wrong answer.
An AI course can show you what the technology can do. It may teach you the vocabulary, the common tools, the architecture patterns, the risks, the current direction of travel. Useful, yes, but a technology leader is not paid to know that AI exists.
A technology leader is paid to decide where it creates value, where it introduces risk, where it changes operating models, where it saves money, where it wastes money, and where it becomes a distraction dressed up as innovation.
That distinction matters more than people think it does, because the board does not usually ask a clean technical question. They do not say:
“Can we safely introduce an AI-assisted reporting workflow with clearly defined data ownership, permission boundaries, operational accountability, and measurable productivity gains?”
Instead, what you get is simply:
“Can we use AI for reporting?”
Or, even more common:
“Why are we not using AI here?”
Or:
“Our competitors are doing more with AI. What are we doing?”
That question lands on the desk of the technology leader. And the wrong response is to immediately open a workflow builder.
The right response is to slow the conversation down just enough to make it useful.
This is where the executive-level technology education becomes more relevant than a narrow AI module.
Strategic Executive-Level Education vs. Tactical AI Course/Module
Take Module 3 of the Digital MBA for Technology Leaders. It covers tech strategy and business goals. Seasoned practitioners teach leaders to connect technology activity to business strategy rather than treating implementation as the strategy itself.
That module includes lectures such as “What is the Business Strategy and Goals?”, “Where Tech Drives Strategic Competitive Advantage”, “CTO Input into Business Strategy”, “Unpacking Measurement Tools (SMART, OKR, KPI)”, “How to Appraise the Business Drivers”, and “Communicating Roadmap Across Organization.”
That is the actual work behind a good AI decision.
It’s not the prompt, the agent, the workflow, or the decision.
If the CEO asks for AI reporting, the leader trained in this way does not start with the model, but with the business driver. If nobody can answer that, then AI is not yet a solution. It is a symbol. And symbols make terrible roadmaps.
The next problem is ownership
AI initiatives often fail because nobody has defined where business responsibility ends and technical responsibility begins. A developer can build the workflow, but a developer should not be left to decide whether the workflow represents the right business process, the right data definition, the right risk appetite, or the right success measure.
That is a leader’s responsibility.
This is where modules that cover the business become important. Lectures such as “What Matters for the CEO and Investors,” “Current Business Position & Market Analysis,” “Building and Cementing Value in a Business,” “The Business Model Canvas,” “Strategic Thinking with AI,” and “What Is a Value Proposition?” develop the commercial judgement needed to decide whether an AI initiative deserves attention in the first place.
Because “we can automate this” is not the same as “this matters.” In practice, this means any or all of the following statements:
A technically impressive AI project can still be strategically irrelevant.
A faster report that nobody uses is not a transformation.
A chatbot that creates more support tickets than it resolves is not innovation.
A dashboard that makes bad data easier to consume is not progress.
A workflow that saves two hours but introduces a compliance risk is not efficiency.
This is the part aspiring leaders often miss when they chase AI courses as career insurance. They assume the risk is not knowing enough about AI. In reality, the greater risk is being unable to govern AI inside a living business.
That requires product thinking.
The necessity of product thinking
Substance in product development matters because many AI initiatives should be treated less like technology experiments and more like product hypotheses. “Defining Your Product Hypothesis,” “Managing Stakeholders,” “Working With Cross Functional Teams,” “Cost/Quality/Speed Triangle,” “Technical Debt,” “Who Should Code,” and “Modern Approaches to Quality & Testing” are not abstract leadership topics. They are the operating discipline behind AI adoption.
In other words, before a workflow is built, someone has to define the hypothesis, and that someone is a technology leader.
For example:
“If we automate the first draft of monthly board reporting for the finance and operations teams, we believe we can reduce manual preparation time by 40% without reducing accuracy or increasing compliance risk.”
Now we have something to test. We have a:
User.
Process.
Measurable gain.
Constraint.
Reason to proceed.
That is leadership.
Think of it this way. The AI course might help someone build a prototype. The executive leadership program, on the other hand, helps you decide whether the prototype should exist, how it should be tested, who should own it, what risk it creates, and how it connects to business outcomes.
The harder question
Then comes the harder question: what information is the AI actually using?
This is where most executive AI conversations become dangerously shallow. People talk about models, agents, prompts, and automation. Far fewer talk about data quality, access control, deletion, reporting lines, system ownership, auditability, and business continuity.
Yet these are the issues that decide whether AI can be used safely at scale.
This is not separate from AI. It is the foundation beneath AI.
If a company has unclear data ownership, weak access control, poor documentation, messy SaaS sprawl, inconsistent reporting, and no real view of operational risk, then AI will not magically create clarity. It will just amplify the mess.
A leader needs to know that before implementation starts. However, it is easy to miss that without broader leadership knowledge and perspective. As practice shows, leaders often learn about pre-existing issues only after the first incident or after the board asks why sensitive information appeared in the wrong place, or, which is even more common, after a team builds a tool nobody can maintain.
This is also why the financial side matters.
The financial side of business
AI adoption is now often sold internally as inevitable. But inevitability is not a budget. Someone still has to justify spending, compare priorities, manage trade-offs, and explain expected return. A deep understanding of financial mechanisms inside the business becomes really important when AI moves from experiment to operating cost. Because if things go south, it’s the tech leader who takes the hit.
Even pilot projects generate technical debt and financial business expense.
A leader who cannot speak finance will struggle to defend the right AI investment or kill the wrong one.
That second part is just as important because the market is full of AI projects that should never have been approved. Not because the technology was bad, but because the business case was lazy, the costs were vague, the risks were underestimated, the benefits were assumed, the ongoing maintenance was ignored, and the operational change was treated as someone else’s problem.
A strong technology leader protects the company from that by introducing the necessary level of discipline and making it useful.
Then, of course, there is data, because as a rule of thumb, an AI strategy is impossible without a data strategy.
Being a CTO doesn’t mean becoming a data scientist. It means understanding enough to ask better questions, something taught by technology leadership programs. Students learn the right leadership questions that determine whether AI becomes a credible business capability or another layer of noise and, ultimately, a liability.
The Digital MBA, for instance, includes AI-specific content. Lectures such as “Lessons from Building a Customer GenAI Agent,” “Context Coding,” “Embracing Transformative Opportunities with AI,” and “Building Internal Tools with AI: From Idea to Working Software” go deep into the subject from a practical standpoint because of the challenges these topics present. But the important point is that AI appears in context throughout the entire course, and that is how leaders should learn it.
It shouldn’t be a standalone obsession, a panic purchase, or a new identity because AI belongs inside business strategy, product development, finance, data, operations, information management, security, culture, and executive communication. That is where it has to work.
So the core message for anyone trying to move from senior technologist to executive technology leader is this:
You do not need to become the person who manually wires every AI workflow together.
You need to become the person who knows which workflows deserve to exist.
In other words, you need to know how to:
Connect workflows and agentic orchestrations to strategic goals.
Measure their value.
Manage their risk.
Explain them to non-technical stakeholders.
You also need to know when to say yes, when to say no, and when to say: “Not until we understand the problem properly.”
That is not developer training.
It is executive training.
And the current AI moment has made this distinction more important, not less.
Companies are under pressure to act. Boards want AI plans. CEOs want productivity gains. Investors want efficiency. Teams want clarity. Customers want better experiences. Regulators want accountability. Nobody wants to be left behind.
In that environment, the weakest technology leaders will chase tools.
Only the strongest will create judgment.
They will know how to turn vague executive pressure into a clear business problem. They will know how to separate useful automation from novelty. And they will know how to build the case, protect the organization, align the teams, and measure the outcome.
That is the actual career security.
Not being the person who knows the newest AI platform, but being the person trusted to decide how the organization should use it.
So no, the absence of a dedicated AI module in technology leadership programs is not the weakness people think it is, because these programs are not trying to produce AI developers.
They are designed to produce technology leaders who can use AI responsibly, commercially, operationally, and strategically.
That is the bigger need.
And it is the need that will still exist when the tools change again.
A Chief Technology Officer is the senior technology leader responsible for connecting technical capability with business direction.
In some organizations, the CTO owns product architecture, engineering strategy, platform decisions, and innovation. In others, the role is focused on technology transformation, data, infrastructure, security, or AI adoption. The exact shape depends on the organization’s size, stage, and business model.
What has changed is the level of visibility.
The CTO is no longer judged only on technical depth or delivery performance. The role now carries broader responsibility for how technology creates value, manages risk, supports growth, and shapes the organization’s future capability.
AI has made that responsibility more urgent
Executive teams are asking where AI can improve productivity, where it can create new products or services, where it introduces risk, and how it should be governed. Those questions require strategic judgment, commercial awareness, leadership confidence, and the ability to explain complex trade-offs clearly.
This guide explains what a Chief Technology Officer does, how the role compares with CIO, VP of Engineering, and Head of Engineering, how AI is changing CTO responsibilities, and what skills modern technology leaders need to build CTO readiness.
TL;DR
The CTO role now sits closer to business strategy than traditional technical management.
A modern CTO connects architecture, engineering capability, product direction, security, data, AI, and commercial priorities.
The difference between CTO, CIO, VP of Engineering, and Head of Engineering usually comes down to scope: future direction, internal systems, execution, and team delivery.
AI has increased the pressure on CTOs to guide adoption, manage risk, set guardrails, and turn experimentation into useful outcomes.
The next step for many current and aspiring CTOs is to identify their capability gaps and build a deliberate development path.
Table of Contents
What is a Chief Technology Officer?
A Chief Technology Officer, or CTO, is the senior leader responsible for shaping how an organization uses technology to achieve its goals.
The role sits at the intersection of technology, business strategy, product direction, and organizational capability. As a CTO, you are expected to understand the technical landscape deeply enough to make sound decisions, but the role is not limited to technical expertise. The CTO must also decide which technology investments matter, which risks need attention, and how technical choices affect customers, teams, revenue, resilience, and long-term competitiveness.
The CTO role varies from one organization to another
As the organization matures and expands, so does the scope of the Chief Technology Officer role
In a startup, the CTO may still be close to the codebase, product architecture, hiring, and early engineering culture.
In a scale-up, the role often shifts toward building systems, leadership layers, delivery discipline, and technical foundations that can support growth.
In a larger enterprise, the CTO may focus more on technology strategy, innovation, architecture, governance, AI adoption, and executive-level decision-making.
The common thread is accountability for technology direction
A CTO helps the organization answer questions such as:
What technology capabilities do we need to build?
Which systems should we modernize, replace, or protect?
How should engineering, product, data, security, and operations work together?
Where can emerging technologies such as AI create practical value?
What technical risks could limit growth or damage trust?
How do we turn business priorities into realistic technology decisions?
In other words, they help technical teams understand business priorities, and executive teams understand the consequences of technology choices.
In the AI era, CTOs are expected to explain what AI can and cannot do, where it belongs in the organization, how it should be governed, and what capabilities teams need to use it responsibly.
What Does a CTO Actually Own?
First and foremost, there has to be clear senior accountability for the technology decisions that shape the org’s future capability.
A CTO may own any or all of the following areas directly or strongly influence them through collaboration.
Table 1: CTO ownership
CTO responsibility
In practice
Technology strategy
Defining how technology supports business goals, growth priorities, operational needs, and long-term competitiveness.
Architecture and technical direction
Making decisions about systems, platforms, scalability, interoperability, technical debt, and future flexibility.
Engineering capability
Building the structures, standards, leadership habits, and technical culture that help teams deliver reliably.
Product and platform decisions
Working with product and business leaders to decide what should be built, bought, integrated, improved, or retired.
AI adoption and integration
Identifying practical AI use cases, assessing risks, choosing tools, and integrating AI into workflows, products, and systems.
Data and infrastructure readiness
Ensuring the organization has the data foundations, infrastructure, cloud capability, and operational maturity needed to support modern technology priorities.
Security and resilience
Making sure systems are reliable, secure, compliant, observable, recoverable, and trusted by customers and stakeholders.
Vendor and build-versus-buy decisions
Deciding when to build internally, when to buy, when to partner, and how to manage dependency on external platforms or suppliers.
Executive communication
Translating technical choices into business consequences so CEOs, boards, investors, and senior teams can make informed decisions.
Innovation and experimentation
Evaluating emerging technologies, deciding where to experiment, and turning useful learning into practical adoption.
Technology risk and governance
Creating decision-making frameworks for technology investment, AI use, security, compliance, resilience, and operational risk.
In smaller organizations, one CTO may cover most of these responsibilities directly. In larger ones, many of them will be shared with CIOs, CISOs, product leaders, data leaders, enterprise architects, and engineering executives.
The CTO’s value lies in connecting those moving parts into a coherent technology direction.
CTO vs CIO vs VP of Engineering vs Head of Engineering
The simplest way to understand the difference is to look at the primary focus of each role.
The CTO owns future-facing technology direction, the CIO owns internal technology operations, the VP of Engineering owns engineering execution, and the Head of Engineering usually owns day-to-day team delivery.
Table 2: Primary focus and responsibilities of different roles
Role
Primary focus
Typical responsibilities
CTO
Technology strategy and future capability
Architecture, innovation, AI strategy, technical direction, product-facing technology, and executive advice.
CIO
Internal technology and enterprise systems
IT operations, enterprise software, data systems, compliance, service delivery, and corporate technology services.
VP of Engineering
Engineering execution
Delivery, team structure, engineering processes, quality, hiring, performance, and engineering management.
Head of Engineering
Engineering leadership and management
Team performance, sprint delivery, technical standards, people management, and day-to-day delivery discipline.
By default, the CTO is the role most closely associated with future-facing technology decisions. That can include:
Product architecture
Platform strategy
Emerging technology evaluation
AI adoption
Technical risk
The explanation of technology choices to the board or executive team
CIO vs CTO
Recently, the CIO and CTO roles have been coming closer together and sharing a lot of similar responsibilities. But as a rule of thumb, the CIO is typically more focused on the internal technology estate. This may include enterprise systems, workplace technology, IT operations, data platforms, procurement, compliance, and service management.
In larger enterprises, the CTO and CIO work closely together: the CIO ensures the org runs reliably, while the CTO helps decide how technology should evolve.
VP of Engineering vs CTO
The VP of Engineering is usually responsible for turning technical direction into delivery. This role often owns engineering structure, hiring plans, delivery processes, quality standards, team performance, and execution rhythm. A strong VP of Engineering helps ensure the organization can build and ship reliably.
Head of Engineering vs CTO
The Head of Engineering role is usually more delivery and team-management focused, although the title varies widely. In smaller companies, the Head of Engineering may be the most senior engineering leader. In larger ones, the role may sit below a VP of Engineering and focus on a specific product area, platform, function, or team group.
Donning several hats at once
In early-stage companies, one person may cover several of these responsibilities. A founder CTO might act as CTO, VP of Engineering, architect, hiring lead, and product partner at the same time.
CTO Academy is a great example of that. Jason Noble, the co-founder and CTO, was even engaged as the COO at one point. The reason was simple: he designed the systems and most of the operations, so to maintain the momentum and stay agile, it was simpler to assume that role also than to train somebody else during those early stages.
Unlike startups, in larger organizations, the boundaries are usually clearer, though the CTO still needs to collaborate closely with CIO, product, security, data, and commercial leaders.
In the past, many CTOs were judged mainly on technical oversight: keeping systems running, guiding architecture, supporting delivery, and ensuring engineering teams had the tools and standards they needed. While those responsibilities still matter, they are no longer enough.
Modern CTOs are expected to connect technology decisions to business outcomes.
They need to understand how platforms, data, security, AI, engineering capability, and operating models affect growth, resilience, customer experience, and competitive position.
Table 3: Traditional vs modern CTO role
Traditional CTO emphasis
Modern CTO emphasis
Systems and infrastructure
Platforms, data, AI, security, and scalability.
Technical delivery
Business-aligned technology strategy.
Tool selection
Operating model and capability building.
Architecture decisions
Decisions about speed, resilience, cost, integration, and future flexibility.
Engineering supervision
Cross-functional executive leadership.
Innovation experiments
Measurable transformation and adoption.
Technical reporting
Board-level risk and opportunity communication.
Generic digital transformation
AI-enabled change linked to practical business outcomes.
This shift has changed how CTOs spend their time
The role is less about being the final technical authority on every decision and more about creating the conditions for better decisions across the organization.
A modern CTO:
Helps teams move quickly without creating uncontrolled risk.
Supports innovation without encouraging disconnected experiments.
Modernizes systems without breaking operational reliability.
Explains technical trade-offs in language that boards, CEOs, investors, and commercial leaders can act on.
AI has radically accelerated this change. It has made technology leadership more visible because AI decisions affect product strategy, data quality, security, customer trust, workforce capability, and business performance. That’s why the CTO is increasingly expected to help separate useful adoption from noise and turn emerging technology into governed, measurable progress.
For many existing and aspiring technology leaders, this is the point where the next stage of development becomes less about adding more technical depth and more about building executive range: strategy, communication, commercial judgment, organizational design, and leadership under uncertainty.
Why AI Has Made the CTO Role More Visible
AI has pushed technology leadership closer to the center of business strategy.
Boards and executive teams are pushing for AI adoption. Their questions rarely have purely technical answers, but they do require technical judgment. That is why the CTO has become more visible.
AI is not just a tooling decision. It affects data, workflows, security, governance, teams, customer experience, productivity, and business models. A poorly chosen AI tool can create risk without creating value. A promising AI use case can fail because the data is not ready, the workflow is unclear, or the organization has not decided who is accountable. A useful pilot can remain stuck as an experiment if it is never integrated into core systems or measured against business outcomes.
The CTO’s role is to help move beyond AI enthusiasm and into practical adoption
That means asking:
Where can AI create measurable value for customers, teams, or operations?
Which use cases are worth testing now, and which should wait?
What data, infrastructure, security, and integration work is needed first?
Which AI tools should be bought, built, customized, or avoided?
What guardrails are needed around privacy, compliance, accuracy, bias, and human oversight?
How should teams be trained to use AI responsibly?
How will success be measured beyond novelty or short-term productivity gains?
This is where the CTO becomes a translator between ambition and execution.
The CEO may want speed. The board may want assurance. Product teams may want experimentation. Engineering teams may worry about complexity, reliability, and technical debt. Legal, security, and compliance teams may see new forms of exposure. The CTO needs to connect those perspectives into a clear path forward. They help to decide where AI should be embedded, where it should be controlled, and, more importantly, where it should not be used at all.
This is also why AI leadership has become a development priority for technology leaders. Technical fluency matters, but it is not enough. CTOs need the executive range to assess risk, prioritize investment, influence stakeholders, govern adoption, and explain trade-offs in business terms.
It is a practical guide for integrating AI into core systems without compromising security, control, or leadership accountability.
What Skills Should the Modern CTO Possess
While technical judgment remains essential, it now sits inside a wider leadership skill set. This is one of the biggest shifts for senior technology leaders because many reach the point where technical knowledge is no longer the main constraint. The harder challenge is deciding what matters, influencing people who do not think like engineers, and making technology choices that support the business without creating avoidable risk.
Table 4: Modern CTO skill stack
Skill area
Purpose
Technical judgment
Understanding trade-offs, architecture, scalability, reliability, technical debt, and technical risk.
Systems thinking
Knowing how platforms, teams, workflows, data, security, vendors, and customer experience affect one another.
Strategic thinking
Technology choices need to support business priorities, not just technical preferences.
Product and customer awareness
Understanding how technology decisions affect users, customers, product direction, and market position.
Understanding AI capabilities, limitations, risks, integration demands, and realistic use cases.
Commercial awareness
Investment decisions need to connect to value, cost, growth, efficiency, and competitive advantage.
Security and risk awareness
Recognizing where technology creates operational, reputational, compliance, or customer trust risks.
Communication
Explaining technical complexity to non-technical stakeholders without oversimplifying the consequences.
Executive influence
Shaping decisions with CEOs, boards, investors, product leaders, finance teams, and commercial stakeholders.
Team leadership
Building confidence, alignment, standards, and capability across engineering and technology teams.
Change leadership
Leading transformation across systems, teams, behaviors, workflows, and operating models.
Strategic prioritization
Deciding what to pursue, what to delay, what to stop, and what risks the organization is willing to accept.
Governance
AI, security, data, architecture, vendor, and platform decisions need clear accountability and decision-making discipline.
The balance of these skills changes as the role becomes more senior. Earlier in a technology career, credibility often comes from technical depth and delivery. At the CTO level, credibility comes from judgment: knowing which technical issues matter most, how they affect the business, and how to bring people with different priorities into a shared decision.
AI has made that skill stack more demanding
CTOs now need enough technical fluency to challenge hype, enough commercial understanding to prioritize valuable use cases, enough governance discipline to manage risk, and enough leadership range to help teams change how they work.
For aspiring CTOs, this can be a useful way to assess readiness. The question is not simply “Am I technical enough?” It is also “Can I influence strategy, communicate trade-offs, lead through uncertainty, and connect technology decisions to business value?”
The best way to assess where you are right now is to benchmark your skill set against those who were in your shoes until most recently.
Use it to identify your strengths, gaps, and development priorities as a current or aspiring technology leader.
AI Leadership Responsibilities for Chief Technology Officers
CTO must decide where AI fits, how it should be used, what risks need to be controlled, and how adoption will create measurable value.
That responsibility usually falls across five connected areas: strategy, integration, governance, risk, and adoption.
AI Strategy
The CTO should help define how AI supports the organization’s business goals.
This means moving beyond general enthusiasm and identifying where AI can improve products, customer experience, operational efficiency, decision-making, engineering productivity, or internal workflows.
The CTO does not need to own every business case, but they should help test whether proposed AI initiatives are technically realistic, commercially useful, and aligned with the priorities.
Useful questions include:
Which AI use cases are most likely to create measurable value?
Which opportunities depend on better data, systems, or process maturity?
Which experiments are worth running now?
Which ideas are interesting, but not yet ready for investment?
How will AI priorities connect to product, operations, customer, and revenue goals?
Without this strategic filter, AI activity can become scattered. Teams may experiment in different directions, vendors may shape the agenda, and the organization may confuse visible activity with real progress.
AI Integration
The CTO is responsible for making sure AI can work inside the orgs’ existing technology environment.
AI tools rarely create value in isolation. They need to connect with data, workflows, platforms, APIs, security controls, customer journeys, and operational processes. A promising AI use case can easily fail if it cannot access reliable data, fit into existing systems, or support the way teams actually work.
The CTO needs to consider the following factors:
Where AI should sit in the architecture
How models and tools will connect to existing systems
What data is required, and whether it is trustworthy
How outputs will be checked, monitored, or reviewed
How AI-enabled workflows will affect teams and customers
What technical debt or infrastructure constraints need to be addressed
This is where AI moves from experiment to implementation. The CTO’s job is to avoid isolated pilots and build the technical foundations needed for repeatable adoption.
Good AI governance should, therefore, make the following points very clear:
Who can approve AI tools and use cases
What data can and cannot be used
When human review is required
How AI outputs should be tested
How vendors are assessed
How risks are escalated
How performance and unintended consequences are monitored
Governance is especially important as AI adoption spreads across departments. Without clear guardrails, different teams may adopt tools independently, expose sensitive data, duplicate costs, or create inconsistent customer and employee experiences.
AI Risk
AI creates new forms of technology and business risk. The CTO ensures that the organization understands those risks without unnecessary lag in useful progress.
Key areas include security, privacy, compliance, bias, reliability, explainability, intellectual property, vendor dependency, and operational resilience.
Some risks are purely technical. Others, on the other hand, are organizational. However, many sit between technology, legal, security, HR, product, and customer-facing teams.
The CTO should answer questions such as:
What happens if an AI system produces inaccurate or misleading output?
What data is being shared, stored, or used for model training?
Which AI decisions need human oversight?
How do we prevent sensitive information from being exposed?
What happens if a vendor changes pricing, access, performance, or terms?
How do we test AI systems before they affect customers or critical processes?
The goal is not to block AI adoption but to make adoption safe, clear, and controlled enough to be trusted.
AI Adoption
AI leadership also requires preparing people to work differently.
The CTO has a mandate to help teams understand how AI should be used, where it can support their work, and where judgment still matters. This includes engineering teams, product teams, operations, customer support, data teams, and senior leadership.
Adoption depends on far more than just tool access. Teams need guidance, examples, training, workflows, and confidence, especially non-tech teams. They also need to understand the limits of AI, including when outputs need to be checked and when automation is inappropriate.
The CTO should help create the conditions for responsible adoption by:
Supporting practical training
Encouraging useful experimentation
Sharing/controlling approved tools and patterns
Defining acceptable use
Building feedback loops
Measuring impact
Helping managers adapt workflows
Reinforcing where human judgment remains essential
Effective CTOs treat AI adoption as an organizational capability, not a one-off project.
A playbook for turning AI ambition into secure, governed, and commercially useful implementation and moving from assistants to autonomous workflows.
Common Types of CTO Roles
There is no single version of the CTO role. The title can mean different things depending on the orgs’ size, stage, sector, product model, and leadership structure.
This is why two CTOs can have the same title but very different working weeks, as we often hear during weekly expert sessions and inside the Community discussions. One may be close to product architecture and engineering delivery. Another may spend most of their time with the board, regulators, enterprise customers, or transformation teams. Another may focus almost entirely on AI, data, platforms, and operating model change.
The most useful way to understand the variation is to look at the type of CTO role the organization needs.
Creating systems, processes, leadership capacity, and technical foundations that can support growth.
Enterprise CTO
Aligning complex technology estates with business strategy, governance, security, and long-term transformation. May also be a Group CTO, managing several verticals.
Providing senior technology leadership on a fraction of a project/scope for a fraction of the time.
AI-focused CTO
Leading AI strategy, integration, governance, platform choices, and organizational capability building.
These types are by no means fixed categories. In practice, CTO roles often combine several of them. A scale-up CTO may also be product-led. An enterprise CTO may also be responsible for transformation. A fractional CTO may be brought in specifically to support AI adoption, architecture decisions, or technical due diligence.
If you are interested in learning more about different types of CTO contracts, go here.
The important point is context
A strong CTO in one environment may not be the right fit for another. The skills needed to build a technical team from scratch are not identical to the skills needed to modernize a legacy enterprise estate, govern AI adoption, or advise a board on technology risk.
For aspiring CTOs, this distinction is useful because it helps clarify the type of role you are preparing for. For organizations, it helps define what kind of technology leadership is actually needed. A hiring brief that simply says “CTO” is rarely enough. The better question is: what technology challenge does this CTO need to lead?
The first 90 days are not just about proving technical authority. They are about understanding the organization, building trust, identifying constraints, and deciding where technology leadership can create the most immediate value.
A new CTO needs to learn before they prescribe. That means getting close to the business context, not just the technology estate:
What is the organization trying to achieve?
Where is growth being blocked?
Which systems are fragile?
Where are teams moving too slowly?
What risks are already visible?
What expectations does the CEO, board, or executive team have for the role?
In the first 90 days, a CTO should, therefore, focus on:
Understanding the business model, strategic priorities, and commercial pressures
Assessing people, systems, architecture, delivery performance, and technology risk
Building relationships with executive peers, product leaders, engineering teams, data, security, finance, and operations
Identifying technical debt, delivery constraints, capability gaps, and organizational bottlenecks
Clarifying expectations with the CEO, board, founder, or executive sponsor
Finding early credibility-building wins without rushing into cosmetic change
Creating a realistic technology leadership agenda for the next stage
The biggest mistake is to arrive with a fixed answer before understanding the context.
A CTO who moves too quickly can damage trust, misread the organization, or solve the wrong problem. A CTO who moves too slowly can lose momentum and allow existing risks to deepen.
The goal is to build enough understanding to make better decisions
By the end of the first 90 days, the CTO should be able to explain where technology is supporting the business, where it is constraining progress, which risks require attention, and what priorities should shape the next phase of leadership.
Technical problems often have boundaries. Executive leadership problems rarely do. A CTO may need to make decisions with incomplete information, balance competing priorities, defend investment choices, manage risk, and explain why the best technical answer is not always the best organizational answer.
Table 6: The list of connected capabilities that assess CTO readiness
Readiness area
Practical impact
Strategic thinking
Understanding how technology choices support growth, resilience, customer value, and competitive position.
Business and finance understanding
Reading commercial context, investment trade-offs, budgets, margins, cost structures, and value creation.
AI and technology fluency
Knowing where emerging technologies can create value, where they introduce risk, and what foundations are needed for adoption.
Executive communication
Explaining technical trade-offs clearly to CEOs, boards, investors, and non-technical stakeholders.
Decision-making under uncertainty
Making informed choices when the data is incomplete, the risks are uneven, and the answer is not obvious.
Stakeholder management
Building trust across product, engineering, data, security, finance, operations, commercial teams, and executive leadership.
Team leadership
Creating the standards, structures, culture, and leadership capacity that help teams perform.
Governance and risk
Establishing clear decision-making around architecture, AI, security, data, vendors, compliance, and operational resilience.
Personal leadership maturity
Developing self-awareness, resilience, confidence, and the ability to lead through pressure and ambiguity.
The CTO has to move between levels: deep enough to understand consequences, broad enough to guide direction.
For aspiring CTOs, the development path often starts by identifying which gaps matter most. Some leaders need stronger commercial confidence. Some need more experience influencing senior stakeholders. Others need to improve strategic prioritization, AI governance, or organizational leadership. The answer often depends on the role they want, the organization they serve, and the risks they are expected to manage.
This is where structured development helps because the CTO role is not learned through technical experience alone. It requires exposure to strategy, finance, leadership, innovation, communication, and decision-making in complex environments.
Identify your strengths, gaps, and development priorities before deciding your next step.
Related Resources for Current and Aspiring CTOs
The CTO role changes with context. A new CTO, an aspiring CTO, an engineering leader preparing for executive responsibility, and an experienced technology leader responding to AI will not all need the same next step.
Use these resources to continue from the area most relevant to your current challenge.
Table 7: The list of relevant resources for CTOs
Resource
Who it is for
Next step
First 90 Days as CTO
For new CTOs who need to establish credibility, assess the organization, and set clear leadership priorities.
CTO stands for Chief Technology Officer. It is a senior leadership role responsible for technology direction, technical capability, and the connection between technology decisions and business goals.
What does a Chief Technology Officer do?
A Chief Technology Officer leads technology strategy and helps align technical decisions with business priorities. Depending on the organization, a CTO may be responsible for architecture, engineering capability, product technology, AI adoption, innovation, security, governance, vendor decisions, and executive communication.
Is a CTO higher than a VP of Engineering?
Usually, yes. A CTO is typically more strategic and executive-facing, while a VP of Engineering is usually more focused on engineering execution, delivery, team performance, process, and quality. In smaller companies, however, the distinction can be less formal. One person may cover both roles, or the VP of Engineering may operate with responsibilities that look similar to a CTO role.
What is the difference between a CTO and a CIO?
A CTO usually focuses on technology strategy, product technology, innovation, architecture, future capability, and emerging technologies such as AI. A CIO usually focuses on internal technology systems, enterprise applications, IT operations, data infrastructure, compliance, service delivery, and corporate technology services. The two roles often work closely together, especially in larger organizations where technology strategy and internal systems need to be aligned.
What skills does a CTO need?
A CTO needs technical judgment, strategic thinking, business awareness, communication, leadership, AI fluency, security awareness, and the ability to manage trade-offs. As the role becomes more senior, the CTO also needs stronger executive influence, commercial understanding, governance discipline, team leadership, and decision-making under uncertainty.
How has AI changed the CTO role?
AI has made the CTO role more visible because organizations need senior technology leadership to assess use cases, manage risk, integrate tools, govern data, and explain AI’s business impact. AI is not only a technical issue. It affects workflows, products, customer experience, security, privacy, compliance, workforce capability, and operating models. The CTO helps the organization decide where AI can create value and how it should be adopted responsibly.
How do you become a CTO?
Most CTOs build experience across engineering, architecture, product, leadership, strategy, and executive communication. The path often starts with technical credibility, then expands into team leadership, delivery ownership, stakeholder management, business understanding, and strategic decision-making. Structured leadership development can help technical leaders prepare for the broader responsibilities of the role.
Key Takeaways
The CTO role is no longer defined by technical seniority alone, but by the quality of judgment a leader brings to business-critical technology decisions.
AI has raised the stakes because technology choices now affect more than systems and delivery. They shape how organizations compete, manage risk, build capability, and earn trust.
So, for current and aspiring CTOs, the real question is not simply whether they understand the technology. It is whether they can turn technical understanding into strategy, influence, governance, and measurable business value.
That shift rarely happens by accident. Even if it does, the gaps it creates are too large to overcome. The optimal path requires deliberate development across leadership, commercial thinking, communication, AI readiness, and executive decision-making.
The move from Engineering Manager to VP of Engineering can be a painful experience if you fail to understand that the job is no longer about how well one team executes but about whether the wider engineering organization performs reliably at scale.
Strengths in delivery, judgment, and team leadership are no longer enough.
At the VP level, the challenge isto design the conditions in which multiple teams, managers, and cross-functional partners can execute well without constant intervention.
This article will make that shift explicit, drawing from weekly Expert Q&A sessions hosted by CTO Academy and interviews with Engineering Managers and VPs of Engineering, many of whom are members of the Academy’s broader tech leadership community. It will show what actually changes, where strong managers often struggle, and what evidence proves you are ready to operate at VP scope rather than simply aiming for it.
TL;DR
Moving from Engineering Manager to VP of Engineering is not a bigger version of the same job. It is a shift from leading team execution to leading organizational performance.
VPs are judged less by what they deliver directly and more by whether the wider engineering organization can scale, adapt, and perform consistently through other leaders.
Readiness for VP scope is proven by org-level evidence: stronger managers, better prioritization, healthier systems, clearer cross-functional decisions, and execution that does not depend on personal rescue.
Common transition traps include staying too close to delivery, confusing visibility with influence, underinvesting in manager quality, and relying on heroics instead of systems.
The real question is not whether you are capable of more. It is whether you are building proof in the areas that define VP-level leadership: organisational design, strategic prioritisation, executive influence, and leadership leverage.
Table of Contents
Get the IT Career Path Roadmap (Free PDF)
Want more than scattered ideas? Get our IT Career Path Roadmap PDF – an 8-step framework to map your next roles, sharpen your skills, and build a layoff-resilient tech leadership career. Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
Engineering Manager vs VP of Engineering at a Glance
In practical terms:
An Engineering Manager is (usually) accountable for helping a team deliver well: strong execution, healthy people management, and dependable local decisions.
A VP of Engineering is accountable for whether the broader engineering organization can perform consistently through structure, planning, management quality, and cross-functional alignment.
To better understand the environment you must build, we need to compare the two roles side-by-side, as presented in the table below.
TABLE 1: Direct comparison between the two roles
Dimension
Engineering Manager
VP Engineering
Primary focus
Team execution, delivery quality, and manager-to-team effectiveness
Organizational performance, leadership quality, and execution consistency across the function
Scope
One team or a small cluster of teams
Multiple teams, managers, and the operating system connecting them
Time horizon
Sprint to quarter
Quarter to multi-quarter horizon
Stakeholders
Engineers, direct reports, product counterpart, immediate peers
Executive team, senior cross-functional leaders, managers, and the wider engineering organization
Key decisions
Delivery trade-offs, staffing on the team, local process improvements, and team health interventions
Staying too tactical, over-owning delivery details, and solving too much directly
Mistaking visibility for leverage, weak manager bench, fragmented planning, and inconsistent standards across teams
Failure mode
The team depends too heavily on one leader to keep execution moving
The organization grows in headcount but not in coherence, judgment, or resilience
Rule of Thumb: VP Engineering leaders succeed by improving the conditions under which many teams and managers perform well, even when they are “not in the room.”
What Actually Changes When You Move from an Engineering Manager to VP of Engineering
Shift #1: From Team Outcomes to Organizational Outcomes
As an EM, you focus on a single team’s health, direction, and delivery. But as a VP of Eng, the question becomes whether the wider engineering organization can produce reliable outcomes across multiple teams, managers, and priorities.
That matters because local success can hide organizational weakness. A few strong teams can keep shipping while planning is uneven, dependencies are poorly managed, or management quality varies widely across the org. That’s why, at the VP level, you have to see beyond team performance and judge whether the system as a whole is working.
The problem is that failure here is really subtle at first. The VPE keeps managing through a team lens, celebrates isolated wins, and misses the fact that overall organizational performance is fragile, inconsistent, or overly dependent on standout individuals.
When you are standing right next to the building, you have to take a few steps back to see the whole structure.
Shift #2: From Direct Management to Leadership Leverage
Engineering Managers often create impact through direct involvement: coaching individuals, unblocking decisions, tightening execution, and stepping in when needed.
A VP of Eng cannot scale that approach because the job is to increase leadership leverage through managers, structure, and clear operating expectations. So, every problem you solve is a problem the organization would not learn to solve without you. The more senior the role, the more dangerous that becomes because what initially feels like support can become a bottleneck.
In practice, this means spending less time rescuing execution and more time strengthening the people and mechanisms that carry it:
Calibrating managers.
Setting expectations for decision quality.
Building clarity around ownership.
Making sure leadership depth is growing.
What does the failure look like at this level?
It is, basically, overload disguised as commitment. The VPE stays involved in too many details, becomes the center of decision-making, and unintentionally teaches the organization to escalate instead of lead.
Shift #3: From Short-cycle Execution to Multi-quarter Planning
At the EM level, the rhythm of leadership is often tied to near-term delivery: sprint progress, immediate staffing issues, next-quarter commitments.
At the VP level, you still care about current execution, but you also have to shape what the organization will be able to do two or three quarters from now.
You see, most organizational problems are created long before they are visible in delivery. Weak planning, thin management coverage, unclear priorities, and poor sequencing do not fail all at once. They surface later, usually when the organization is already under pressure.
This alone changes the nature of your questions in your daily operations. You are not only asking whether plans are on track. You are also asking whether the current shape of the organization will support the roadmap ahead, whether leadership capacity matches growth, and where future strain is building.
How to know you are failing?
Failure here shows up as reactive leadership. The VPE spends every quarter dealing with predictable problems that should have been addressed earlier through planning, structure, or clearer trade-offs.
Shift #4: From Local Optimization to Cross-functional Alignment
Engineering Managers can often improve results by optimizing the team around them: better rituals, sharper priorities, stronger execution habits.
A VP of Eng has to think beyond local optimization to align engineering with product, design, finance, security, and executive priorities so that the organization can move coherently.
Engineering performance is shaped by the quality of decisions made around engineering, not just inside it. Misalignment across functions creates churn, conflicting expectations, and avoidable rework at scale.
In day-to-day leadership, this means spending more time on shared planning, decision clarity, expectation-setting, and trust with peers outside engineering. To put it bluntly, you are not just defending engineering capacity but also helping create a model in which functions can make better trade-offs together.
What does the failure look like?
Failure looks like an organization that works hard, but pulls in different directions. Teams stay busy; however, priorities shift, dependencies stall, and engineering absorbs the cost of poor cross-functional decisions without fixing the underlying pattern.
Shift #5: From Problem Solver to Operating System Builder
Strong Engineering Managers are often valued because they solve hard problems quickly. While that instinct remains useful, a VP leadership level depends far more on building an operating system that prevents repeat problems, surfaces risk early, and enables better decisions across the organization. This is the highest-stakes shift because it determines whether the organization can scale.
An operating system in this context is the set of planning rhythms, decision forums, management expectations, accountability mechanisms, and communication patterns that make performance repeatable.
In practical terms, this means designing how the organization runs. To give you a clue, here’s the 5 Hows Framework you must ask:
How are priorities set?
How are trade-offs escalated?
How is delivery health reviewed?
How are managers developed?
How are standards kept consistent across teams?
How to know you’re failing?
Failure here looks like chronic dependence on individual effort. The organization keeps moving through heroics, intervention, and informal workarounds, but never becomes more resilient, more predictable, or easier to lead.
6 Competencies That Separate Strong Managers from VP-level Leaders
The clearest way to assess VP of Engineering readiness is to stop asking whether someone is a strong manager and start asking whether they can build, run, and improve an engineering organization through other leaders.
That is the real threshold. At this level, competence is not defined by personal effectiveness alone. It is defined by whether the leader creates better organizational outcomes through structure, decisions, systems, and leadership leverage.
1. Organizational Design
At the VP level, organizational design means shaping the structure (of engineering) so that ownership is clear, decision-making is efficient, and the organization can scale without collapsing into confusion or dependency.
What does a strong behavior look like?
Matching team boundaries to product and business needs.
Clarifying decision rights.
Adjusting the structure before growing complexity turns into friction.
What does a weak behavior look like?
Treating org design as an occasional reshuffle.
Inheriting structural problems for too long.
Solving systemic friction with extra meetings and heroic coordination.
What is evidence of readiness?
Readiness is visible in the shape of the organization:
Developing managers who can independently run teams.
Making sound trade-offs.
Leading through ambiguity without constant intervention.
Knowing when to coach, when to stretch, and when to make a change.
Tell-tale signs of weak behavior
Weak behavior usually hides behind helpfulness.
The leader stays too close to important decisions, steps in too often, and becomes the quality-control layer for too much of the organization.
Output may still look good in the short term, but the management bench stays thin.
Evidence of readiness
It is not “my team likes me” or “I mentor people.” It is a stronger leadership layer:
Managers grow, taking on a larger scope successfully.
The organization becomes less dependent on senior intervention because leadership capability has spread rather than concentrated.
3. Strategic Planning and Prioritization
At the VP level, planning is the discipline of turning business priorities into realistic engineering commitments, sequencing work across multiple teams, and protecting the organization from overload and confusion.
Signs of strong behavior
Making clear trade-offs.
Exposing capacity constraints early.
Translating strategy into execution choices.
Resisting the temptation to say yes to everything.
The result is predictable: too many commitments, constant reprioritization, and delivery pressure that feels operational but is actually strategic failure upstream.
Evidence of readiness
Evidence shows up in the planning outcomes:
Roadmaps become more credible.
Trade-offs are visible earlier.
Teams understand why work matters and how it fits together.
Fewer surprises appear late in the quarter because the organization has become better at choosing, sequencing, and declining.
4. Operational Excellence at Scale
Operational excellence at the VP level is about building repeatable mechanisms that improve visibility, execution quality, and resilience across the engineering organization.
Indicators of strong behavior
Establishing clear operating rhythms, common expectations for delivery health, useful performance signals, and escalation paths that surface risk before it becomes failure.
The leader knows where consistency matters and where flexibility is healthy.
Weak behavior appears in two common forms
One is chaos disguised as empowerment, where each team runs differently, and no one can see problems until they are already expensive.
The other is bureaucracy disguised as maturity, where the organization accumulates reporting and rituals without improving decision quality or execution reliability.
Evidence of readiness
Evidence is found in how the organization runs under pressure:
Delivery is more predictable.
Risks are visible earlier.
Cross-team execution improves.
Problems get addressed through operating mechanisms rather than personal heroics.
The system does more of the work, which is exactly what should happen at this level.
5. Executive Communication and Influence
A VP of Engineering must shape decisions beyond engineering. That requires communicating with clarity, earning trust across functions, and influencing senior stakeholders without relying on technical depth alone.
What does strong behavior look like?
Framing issues in business terms.
Surfacing risks without drama.
Presenting trade-offs clearly.
Helping peers make better decisions with engineering rather than around it.
A strong VP-level leader can move between technical credibility and executive relevance without losing precision.
Signals of weak behavior
It looks like over-explaining technical detail, under-explaining organizational risk, or communicating only when something has already gone wrong.
It also shows up when a leader protects engineering locally but fails to influence the broader decisions that create engineering problems in the first place.
Evidence of readiness
Look at stakeholder behavior for evidence:
Executives trust this person’s judgment.
Cross-functional peers involve them early.
Their recommendations shape priorities, investment decisions, and operating expectations.
All of this means that they are not merely present in senior conversations. They improve the quality of those conversations.
6. Succession and Talent Systems
A VP of Eng is responsible for current performance and whether the organization can sustain and renew leadership over time.
Indicators of strong behavior
Building hiring standards.
Creating real development paths.
Identifying future leaders early.
Treating succession as an operating responsibility rather than an emergency response.
This includes knowing where the bench is strong, where it is thin, and where the organization is overexposed to a few key people.
Signals of weak behavior
Treating talent as episodic hiring.
Relying on intuition rather than systems, or discovering too late that leadership depth is missing in critical areas.
Such organizations often look stable until someone leaves, growth accelerates, or a weak manager becomes an organizational bottleneck.
Readiness Matrix
This matrix answers a simple question: Are you still operating as a manager, or already thinking like a VP?
TABLE 2: Readiness Matrix
Dimension
Strong Engineering Manager
Emerging VP
Proven VP-level behavior
Planning
Delivers team commitments well and manages near-term trade-offs effectively
Influences quarterly planning beyond their own team and flags dependency risks early
Shapes multi-team planning quality, forces real trade-offs, and improves roadmap credibility across the organization
Org design
Works effectively within the current structure and spots local friction
Sees where ownership, spans, or team boundaries are starting to break down
Redesigns structures, accountabilities, and interfaces so execution improves at the organizational level
Stakeholder leadership
Builds trust with immediate product and engineering counterparts
Handles broader cross-functional conversations with growing credibility
Influences senior stakeholders consistently and improves the quality of decisions across functions
Manager development
Coaches senior ICs and supports first-line managers well
Begins to raise the management bar and develops leaders with more independence
Builds a stronger leadership bench, calibrates managers clearly, and reduces dependence on senior intervention
Metrics
Tracks team health, delivery, and local performance signals
Connects team metrics to broader delivery and planning questions
Hires well for one team and maintains a strong local bar
Helps shape hiring across adjacent teams or functions
Builds hiring quality as a system through role clarity, evaluation discipline, and long-term talent needs
Decision-making
Makes strong local decisions and resolves ambiguity for the team
Handles broader trade-offs with a reasonable business context
Creates decision frameworks, clarifies decision rights, and improves judgment quality beyond their own span
Cross-functional influence
Collaborates well with nearby peers and protects team delivery
Contributes constructively to wider planning and prioritization conversations
Shapes priorities, trade-offs, and operating expectations across the business, not just inside engineering
The pattern to look for is not perfection. It is repeatability. If most of your strongest evidence still sits in the first column, you are likely operating as a high-performing manager. If you are showing credible behavior in the middle column across several rows, you may be in the transition already. If the third column describes how your organization experiences you consistently, not occasionally, that is much closer to real VP-level readiness.
TIP: Ask yourself which set of behaviors other people would actually recognize in how you lead today?
Why High-Performing Engineering Managers Struggle with the Leap
It’s not because they lack talent, but because the rules have changed. Behaviors that create success at the team level become incomplete, and sometimes counterproductive, at the organizational level.
There are five distinct challenges that EMs are facing after transitioning into the senior role:
1. Staying Too Close to Delivery
A leader remains heavily involved in execution detail, unblocking too much personally, and keeping a tighter grip on delivery than the role now justifies.
It happens for understandable reasons. Closeness to delivery is often how strong managers originally built trust and results. It feels responsible, especially when standards matter, and the organization is under pressure.
The problem is that at the VP level, such a proximity becomes a structural limit. The leader may keep one area performing well, but the wider organization becomes dependent on intervention rather than being built to run well without it. In other words, execution improves locally while leadership capacity stays shallow elsewhere.
2. Confusing Visibility with Leadership
Some leaders step up in title and exposure, then assume that being present in more meetings, speaking in broader forums, or being closer to executives is the same as operating at the VP level.
That confusion is common because visibility often increases before leverage does. A leader may suddenly have more access, information, and audience, but still operate in essentially the same way.
At the org level, that gap really matters because visibility without system-level influence creates the appearance of seniority without the substance of it. The leader is seen more, but decisions, planning quality, and organizational capability do not improve proportionally.
3. Underinvesting in Manager Quality
A high-performing Engineering Manager often knows how to raise the bar within a team. The harder shift is realizing that VP-level effectiveness depends heavily on the strength of the managers beneath them.
This area is often underweighted because manager development can feel slower and less tangible than delivery. It is easier to fix a plan, resolve a conflict, or step into a decision than to build stronger management judgment over time.
The damage shows up in scale
Inconsistent manager quality creates uneven standards, fragile execution, and a growing need for escalation. Consequently, the organization becomes wider without becoming stronger.
4. Treating Strategy as Someone Else’s Job
As a rule of thumb, Engineering Managers are excellent executors of strategy rather than active participants in shaping it. They wait for priorities to arrive, then focus on delivering them well.
That mindset makes sense at the team level, where clarity and execution discipline are often the right focus. But the VP level requires shaping trade-offs, challenging weak assumptions, and helping turn business goals into realistic engineering commitments.
If that shift does not happen, engineering becomes reactive. The function absorbs priority changes, planning strain, and conflicting demands without influencing the decisions that created them. Delivery pressure rises, but the real weakness sits upstream.
5. Running the Organization on Heroics Instead of Systems
Some leaders keep performance high through sheer personal effort: rescuing projects, resolving gaps informally, smoothing cross-functional tension, and carrying complexity through force of competence. This is particularly present in those who matured in a startup environment and got used to donning several hats at once.
That approach may even work for a while, which is exactly why it is dangerous. It creates the impression that the organization is functioning when, in reality, it is being held together by intervention.
Unfortunately, at the VP level, the cost is cumulative:
Risks surface late.
Quality varies across teams.
Planning stays inconsistent.
The organization never becomes more resilient.
The leader looks indispensable, but that is not a sign of maturity. It is usually a sign that the system is underbuilt.
None of these patterns makes someone a weak leader. In many cases, they are extensions of behaviors that made them successful earlier. The challenge is that the VP of Engineering is not a bigger version of the same job. It demands a shift from personal effectiveness to organizational leverage, from visible effort to repeatable system strength, and from leading through closeness to leading through design.
But there’s a subtle difference depending on the health status of the operations.
When things are going well, a VPE is accountable for the structure, planning rhythm, leadership quality, and operating discipline that allow multiple teams to perform consistently.
When things are not going well, the same role is accountable for seeing risk early, correcting system weaknesses, and restoring execution without reducing the job to personal intervention.
A useful way to think about the role is in three layers.
Layer 1 – Direct Ownership
The engineering organization’s structure.
Planning cadence.
Delivery health across teams.
Manager quality.
Leadership bench.
Execution consistency.
Hiring quality.
Risk visibility.
These are core operating responsibilities.
Layer 2 – Heavy Influence
Stakeholder trust.
Product-engineering alignment.
Prioritization quality.
How engineering trade-offs are understood by the wider business.
The VP may not own every business decision, but they are responsible for shaping the quality of decisions that affect engineering performance.
Layer 3 – Indirect Support
Broader company strategy.
Long-range technical direction.
Executive coordination beyond the engineering function.
This is where it is important not to drift into CTO territory. A VP of Engineering is usually not the ultimate owner of the company-wide technology vision. Instead, they are responsible for making the engineering organization capable of executing that vision coherently.
The role becomes operationally real when you see it this way: a VP of Engineering owns engineering performance as a system. Not just whether teams ship, but whether the organization is structured, led, staffed, and aligned well, and visible enough to handle risk before failure makes it obvious. That is why “managing managers” is far too small a description. The actual job is to make organizational performance dependable.
How AI is Changing the VP of Engineering Mandate
AI is now an organizational capability, not just an exciting new tool to play with, and that dramatically changes the job. You must decide where AI should alter engineering productivity, which workflows deserve investment, and where adoption creates more noise, risk, or false confidence than value.
So the question is no longer, “Are teams trying AI?” It is, “Where does AI materially improve how we operate as an engineering organization?”
In some environments, this will affect coding throughput, testing, incident response, documentation, or internal support workflows. In others, the greater value may come from better planning intelligence, knowledge access, or faster operational decision support. The VP-level task is to make those decisions deliberately rather than letting adoption fragment team by team.
This also raises the bar on manager capability. They don’t need to become AI specialists, but they do need enough AI literacy to judge in three instances:
Where productivity gains are real.
Where quality controls are needed.
Where expectations should change.
Without that, organizations drift into uneven adoption and weak accountability.
The other side of the mandate is governance. AI introduces questions of risk, security, reliability, compliance, and decision discipline. That makes a VP of Engineering increasingly responsible for ensuring that adoption is useful, governed, and operationally coherent. That is the real change: AI is becoming less a tooling conversation and more a leadership judgment about systems, standards, and organizational capability.
What Promotion Committees and Executive Teams Look For
The strongest candidates are the ones whose impact has already started to exceed the scope of their current role. They ask, directly or indirectly, whether this person is already reducing organizational risk, improving leadership quality, and operating effectively beyond the formal boundaries. That is the real test.
Evidence That You Are Already Operating Beyond Your Current Title
One of the clearest signals is a broader scope without visible loss of quality. That might mean influencing multi-team planning, improving execution across adjacent groups, or solving structural problems that were not strictly yours to own.
The key is not extra effort. It is a repeated system-level effect.
Senior decision-makers notice when someone consistently improves outcomes outside their immediate perimeter without creating chaos, dependency, or political noise.
Signals of Executive Trust and Cross-functional Credibility
VP readiness is also judged through trust:
Do peers outside engineering seek your view early, especially when priorities, trade-offs, or delivery risk are unclear?
Can you help shape difficult decisions without retreating into narrow functional language?
Executive teams usually look for calm judgment in ambiguity, not just strong opinions in familiar territory. A leader who can translate engineering constraints into business-relevant choices becomes much easier to imagine at the VP scope.
Proof That You Build Leaders (not dependence)
Another strong signal is what happens beneath you. If the people around you become more capable, more independent, and more reliable over time, that is a serious marker of readiness.
Remember: If everything still improves only when you step in personally, the signal is weaker.
Promotion conversations at this level tend to favor leaders who create leverage through stronger managers, clearer expectations, and better judgment in the layer below them.
10 Self-assessment Questions for a VP of Engineering Role
You may be operating with VP-level judgment in planning or stakeholder leadership while still thinking like a strong Engineering Manager in org design, succession, or leadership leverage.
To be sure, do the following self-assessment. Remember, the goal is not to rate your ambition. It is to test whether your current behavior already reflects organizational leadership scope.
Ask yourself:
Am I responsible mainly for one team’s output, or am I measurably improving performance across multiple teams or managers?
Can I identify structural problems in the organization, not just execution problems inside my own area?
Have I influenced quarterly or multi-quarter planning beyond my immediate team in a way others would recognize?
Are managers beneath me becoming more capable and independent, or does quality still rise mainly when I step in?
Do peers outside engineering trust my judgment on priorities, trade-offs, and delivery risk?
Can I see system health clearly across teams, including where execution is fragile, inconsistent, or overly dependent on individuals?
Have I improved decision-making mechanisms, planning cadence, or operating discipline beyond local team process?
Do I create leadership leverage, or do too many important outcomes still depend on my direct involvement?
Am I thinking actively about succession, bench strength, and where the organization is overexposed to a few key people?
If my title disappeared, would the organization still experience me as someone operating at the VP scope?
Keep in mind that VP readiness is primarily blocked by gaps in organizational experience, leadership range, or evidence that others can already trust you with broader system-level responsibility.
12-month Roadmap to Move from Engineering Manager to VP-level Scope
The following roadmap is not about feeling more senior, but about building the kind of evidence that makes a broader leadership scope credible.
Months 1-3: Map the Gap
Step 1 – Start by identifying where your exposure is still too narrow:
Look across the core VP-level dimensions: org design, planning, manager development, cross-functional influence, hiring quality, and system health visibility.
Do not assess yourself by confidence but by evidence:
Where have you already created impact beyond your immediate team?
Where are you still mostly operating at delivery depth?
TIP: If you get a generic, “be more strategic,” push for more concrete elaboration.
Months 3-6: Build Leverage and Broader Exposure
This is the period to take on work that changes how others experience your scope:
Seek broader planning responsibility.
Lead a cross-team or cross-functional mechanism that improves decision quality, prioritization, or risk visibility.
Propose one meaningful org-level improvement where friction, unclear ownership, or weak operating rhythm is holding performance back.
At the same time, invest more deliberately in manager capability. VP-readiness becomes visible when your impact starts to travel through other leaders.
By this stage, you should have a visible system-level impact, with clear evidence showing you can improve how the organization runs:
More credible planning.
Better cross-functional trade-offs.
Stronger management quality
Clearer accountability.
Healthier execution consistency.
Where to Build the Missing VP Muscles
If this article surfaced an uncomfortable truth, it is probably this: being strong in your current role does not automatically make you ready for the next one.
Many engineering managers already lead large scopes, run complex delivery, and carry significant responsibility. The gap usually appears elsewhere. It shows up in organizational design, succession planning, executive influence, cross-functional trade-offs, and the ability to improve performance through other leaders rather than through personal intervention.
That is why the move to VP of Engineering rarely comes from doing more of the same work at a higher intensity. It comes from building capability in a different kind of leadership job.
What is the difference between an Engineering Manager and a VP of Engineering?
An Engineering Manager is usually accountable for team execution: delivery quality, team health, and local decision-making. A VP of Engineering is accountable for organizational performance: structure, planning quality, manager strength, execution consistency, and cross-functional trust across the wider engineering function. The key shift is from direct output to system quality.
How long does it usually take to move from Engineering Manager to VP of Engineering?
There is no standard timeline. In some organizations, the move happens over several role expansions through the Director or Head of Engineering scope. In others, leaders are already carrying VP-level responsibility before the title changes. The better question is not how long it takes, but whether you have built evidence of organizational leadership across planning, manager quality, and system-level impact.
What skills matter most for a VP of Engineering role?
The most important capabilities are organizational design, leadership multiplication, strategic planning and prioritization, operational excellence at scale, executive communication and influence, and succession and talent systems. What matters is not just having these skills in theory, but being able to show that they improve organizational outcomes.
Does a VP of Engineering need to be deeply technical?
A VP of Engineering needs enough technical depth to make sound judgments, challenge weak assumptions, and maintain credibility with engineering leaders. But the role is not defined by being the deepest technical expert in the room. At this level, leadership leverage, planning quality, organizational design, and decision-making matter more than personal technical heroics.
What should I demonstrate before applying for a VP of Engineering role?
You should be able to show a broader scope without loss of quality, stronger leaders beneath you, influence over planning and trade-offs, trust from peers outside engineering, and repeated system-level impact. In practice, that means evidence that you are already improving how the organization runs, not just how your own team performs.
How is the VP of Engineering different from the Head of Engineering or CTO?
Titles vary by company, which is why title politics are not very useful here. In many organizations, the Head of Engineering and VP of Engineering can overlap in scope. CTO is usually a different role, with broader responsibility for technical vision, external technology posture, or company-wide technology direction. VP of Engineering is typically more accountable for turning strategy into dependable engineering performance through structure, planning, leadership quality, and operational discipline.
Conclusion
The move from Engineering Manager to VP of Engineering is not a bigger version of the same role. It is a different leadership job with a different standard of success.
That means two things:
Maturity at the VP level is not measured by how much you personally carry, rescue, or drive.
It is measured by the quality of the system you build: clearer structure, stronger managers, better planning, better decisions, and more resilient execution across teams.
A VP of Engineering is not the person who can handle more. It is the leader who makes the organization stronger, steadier, and less dependent on any one person, including themselves.
CDGO or Chief Digital Growth Officer is a senior executive (C-suite leader) responsible for driving measurable growth through the digital systems that create and capture value: product experience, data and analytics, platforms, and the cross-functional operating model behind them.
In simple terms, a CDGO owns growth outcomes (revenue, retention, conversion, efficiency) and makes them repeatable through digital strategy, execution, and governance.
Where you’ll see the CDGO role:
Enterprises modernizing digital commerce and customer experience.
Consumer brands scaling eCommerce and omnichannel growth.
SaaS scaleups formalizing product-led growth and experimentation.
Platform businesses optimizing marketplace dynamics through product and analytics.
What you’ll get from this guide:
A clear, practical definition of the CDGO role (and how it differs from CDO/CGO).
A breakdown of core responsibilities, KPIs, and the operating cadence that CDGOs run.
The most common career paths into the role for tech/product/digital transformation leaders.
What employers expect at the interview level — plus a ready-to-use 90-day plan template.
Realistic salary expectations and compensation patterns across startups, scaleups, and enterprises (UK + US).
TL;DR
A Chief Digital Growth Officer (CDGO) is a C-suite leader who owns growth outcomes—revenue, retention, conversion, and efficiency—by building the digital operating system behind them: product experience, platforms, data/measurement, experimentation, and cross-functional execution.
This guide breaks down the CDGO mandate, the KPI scoreboards by business model (eCommerce, SaaS, marketplaces), how the job runs week-to-week and quarter-to-quarter, what employers screen for in interviews, realistic UK/US compensation expectations, and a practical 30/60/90-day CDGO action plan template you can reuse on day one.
How this guide was built:
This guide synthesizes real-world recruiter/job-post patterns, executive role comparisons (CDO vs CGO vs CDGO), CTO Academy Tech Leaders Community inputs, and a UK salary benchmark for the CDGO title; then translates it into practical cadences, KPIs, and interview-ready artifacts.
Table of Contents
Get the IT Career Path Roadmap (Free PDF)
Want more than scattered ideas? Get our IT Career Path Roadmap PDF – an 8-step framework to map your next roles, sharpen your skills, and build a layoff-resilient tech leadership career. Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
A Chief Digital Growth Officer (CDGO) is a C-suite operator who blends digital transformation leadership with growth accountability. The role exists to turn “digital” from a set of projects into a repeatable growth engine. This is achieved through a multi-layered process that links strategy, product experience, data/measurement, platforms, and cross-functional execution to measurable outcomes (revenue, retention, conversion, efficiency).
CDGO vs CDO vs CGO (simple comparison)
CDGO = the blend. Think of it as a “CDO + CGO” hybrid with a bias toward building durable systems for growth.
CDO (Chief Digital Officer) typically owns digital strategy and transformation: modernizing the business through technology, redesigning customer experiences, and driving cross-functional change. The CDO role is often described as operating at the intersection of business strategy and digital capability, with transformation as the center of gravity.
CGO (Chief Growth Officer)owns growth strategy across functions, keeping customer-centric growth top of mind and coordinating across silos (often spanning marketing, sales, product, and beyond).
CDGO (Chief Digital Growth Officer), on the other hand, owns growth outcomes, but does it through the digital operating system: product/platform roadmap, data and measurement discipline, experimentation, and the operating model that makes growth repeatable. When you compare CDGO job descriptions, you can see that they explicitly combine cross-functional ownership (digital experience, customer insights, growth engineering) with forecasting and executive reporting on growth strategy.
In practice:
CDO = “make the company digital”; CGO = “make the company grow”; CDGO = “make growth happen through digital systems.”
Chief Digital Growth Officer (CDGO) Job Description (summary)
Own digital growth outcomes: revenue, retention, conversion, and efficiency (LTV/CAC, payback).
Define and manage the growth KPI tree and reporting cadence (weekly/monthly/quarterly).
Lead the digital growth roadmap across product experience, platform capabilities, and data/analytics.
Build and scale an experimentation system (hypotheses, testing, learnings, rollout decisions).
Align cross-functional teams (product, engineering, marketing/RevOps, finance) around priorities and trade-offs.
Create executive-ready investment cases and resource plans tied to measurable impact.
Ensure growth scales with governance (privacy, security, compliance, data quality guardrails).
1. There is a constant growth pressure. Leaders want one accountable owner who can unify growth across functions rather than splitting it across marketing/product/tech.
2. For a while now, digital channels dominate growth. The fastest path to revenue, retention, and margin improvements runs through digital experience and platform capabilities – even in OT.
3. Boards now expect growth leaders to run with instrumentation, forecasting, and operational rigor, not “campaign results.” In other words, they expect measurements. Many CDGO job postings emphasize just that: analytics ecosystems, insights, and executive-level reporting on forecasts and projections.
That being said, one question remains: Why would you opt for this particular career path instead, for example, Head of Engineering or CTO?
Why Choose the CDGO Path (instead of staying on the Head of Engineering/CTO track)?
For many senior tech and product leaders, the CDGO path is attractive because it offers broader business ownership and a clearer line of sight to measurable commercial outcomes, all without giving up the strategic leverage of technology. Here is a simple checklist to see if this role is something worth pursuing given your short- and long-term career plans.
You might prefer the CDGO trajectory if you want to:
Own growth outcomes, not just delivery. CTO/HoE roles often get measured on reliability, velocity, cost, and technical quality. In contrast, CDGOs are measured on revenue, retention, conversion, LTV/CAC efficiency, and are empowered to change the system if they have to just to move those numbers.
Operate at the intersection of product, data, and go-to-market. A CDGO role is designed for leaders who enjoy shaping the full growth engine: product experience, experimentation, analytics, lifecycle, and cross-functional execution.
Move from “how we build” to “what we build and why.” Many engineering leaders want more influence over prioritization, investment decisions, and business strategy. That’s why they choose this career path, because CDGO typically sits closer to the portfolio and P&L conversation.
Become the executive who makes growth repeatable. Rather than being pulled into one-off transformations, the CDGO mandate is to build a durable operating system for growth: metrics, governance, cadence, and scalable platforms.
Increase executive leverage (and often compensation upside). The role commonly comes with higher upside through bonuses, equity, and strategic scope, because performance ties directly to business results.
When is the CTO/HoE track the better fit?
It makes sense if your highest motivation is deep technical architecture, engineering excellence, platform reliability, and technical strategy as the primary mandate. CDGO is best for leaders who want technology to be the means, with growth as the scoreboard.
Universal Responsibilities of a CDGO Role
Universal Responsibilities of a CDGO Role – visual presentation of four main categories with outcome ownership areas
The title varies by company, but the CDGO mandate is remarkably consistent: own growth outcomes and build the digital systems and operating model that make those outcomes repeatable. If you’re reading CDGO job descriptions and they feel inconsistent, use this as your canonical checklist (these responsibilities show up whether the company is a startup, scaleup, or enterprise):
1. Growth Accountability (outcomes)
A CDGO is accountable for measurable growth. That doesn’t always mean they “own Sales,” but it does mean they own the growth levers the business can reliably pull through digital channels.
Typical outcomes that a CDGO is expected to move:
Revenue levers: digital revenue growth, ARPA/ARPU, average order value, and expansion revenue.
Unit economics: LTV, CAC, CAC payback, contribution margin, cost-to-serve efficiency.
Growth efficiency: experimentation velocity, time-to-impact, ROI on digital investments.
2. Digital Systems Ownership (means)
CDGO is not a “growth strategy in a slide deck.” Instead, it is growth through a digital operating system that is capable of making improvement continuous, measurable, and scalable.
Core “means” a CDGO typically owns or heavily influences:
Digital experience: customer journeys, UX, performance, personalization, friction removal.
Chief Digital Growth Officer’s work is inherently cross-functional because growth is cross-functional. The role exists to align teams that otherwise optimize locally (e.g., engineering for delivery, marketing for campaigns, finance for cost control) into one coherent growth system.
This is how orchestration works in practice:
Align product, engineering, marketing, RevOps, and finance around a shared KPI tree and priorities.
Translate business goals into a sequenced portfolio (not a backlog) with clear owners and measurable impact.
Build an executive-ready narrative: what we’re doing, why it matters, what’s working, what’s not, and what we’re changing.
Run the communication layer: stakeholder management, expectation-setting, trade-off calls, and decision clarity.
4. Governance & Risk
As a CDGO, you don’t get to choose between growth and control; you must deliver both. That means explicitly managing the trade-offs that appear when you scale experiments, data usage, and automation.
In that role, you are expected to:
Make privacy and consent part of the growth system (not a late-stage review).
Partner with security/legal/compliance to ensure secure-by-design changes and safe experimentation.
Balance speed with risk through guardrails: data governance, model governance (if AI is used), release controls, and auditability.
Protect trust while pursuing performance because “growth at any cost” is a liability in regulated or brand-sensitive environments
Remember:
A CDGO isn’t defined by one department. The role comes down to a single responsibility and that is making growth outcomes repeatable through digital systems, cross-functional execution, and governance.
What Does a Chief Digital Growth Officer Do Day-to-Day?
A CDGO’s calendar looks less like “projects and status updates” and more like an operating system for growth. The job is to create a tight feedback loop between what the business needs, what the digital system is producing, and what gets prioritized next. And all of this with clear decisions, measurable impact, and fast learning cycles.
Let’s go over the operation cadence of CDGOs to better understand how it feels wearing that hat during a single week, a single month, or a quarter.
Weekly Cadence
Weekly rhythms are about speed and signal: spotting what’s moving, what’s breaking, and what requires immediate attention/intervention.
Most CDGOs run a weekly cycle that includes:
Growth review: the KPI dashboard that matters (revenue, retention, conversion, activation, efficiency) and what changed since last week.
Experiment review: what shipped, what learned, what scaled, what stopped, plus “next bets” and resourcing decisions.
Funnel health check: where users/customers drop, friction points, performance anomalies, and cohort movement.
Delivery risk scan: dependencies, data-quality issues, platform bottlenecks, and anything that threatens speed-to-impact.
A practical rule: weekly meetings should end with three decisions: 1) what we double down on, 2) what we pause, and 3) what we change.
Monthly Cadence
Monthly cycles are where the CDGO prevents “activity drift” and keeps the org aligned on the highest-ROI work.
Common monthly motions:
Portfolio reprioritization: adjust the growth roadmap based on evidence, not opinions; in other words, rebalancing bets across acquisition, activation, retention, and monetization.
KPI/OKR calibration: refine targets and leading indicators, tighten definitions, and ensure teams are optimizing toward the same scoreboard.
Budget trade-offs: shift investment toward what works (and away from what doesn’t), aligning spend with measurable performance.
Quarterly is the “board-level” tempo: strategy, investment, capability, and organization design. It’s where the CDGO makes the growth engine more durable and not just faster.
A strong quarterly cycle includes:
Strategy refresh: update the growth strategy based on market reality, customer signals, and performance trends.
Investment cases: define where the next quarter’s growth will come from, and what capabilities (platform, data, product) must be funded to unlock it.
Capability gap review: identify missing competencies (analytics depth, experimentation maturity, product discovery, lifecycle mechanics) and fix them through hiring, upskilling, or org changes.
Org design decisions: clarify ownership boundaries across product, engineering, marketing, RevOps, and finance so execution is faster and accountability is clear.
If you go through CDGO postings, you’ll notice that they explicitly call out planning and forecasting—supporting revenue planning, performance modeling, and long-range initiatives—because quarter-level decisions are where growth becomes a managed system rather than a hopeful outcome.
CDGO KPIs (the scoreboard employers expect you to own)
A Chief Digital Growth Officer (CDGO) isn’t judged by “digital activity.” They’re judged by a scoreboard, which is, in essence, a small set of metrics that prove the digital growth engine is working. The exact KPIs vary by business model, but the pattern is consistent: outcomes + leading indicators + efficiency.
e-Commerce/Consumer KPIs
Revenue & mix
Digital revenue (total and growth rate)
Digital revenue mix (% of total revenue)
Revenue by channel/device/segment
Conversion & basket
Conversion rate (overall + by step)
Average order value (AOV)
Checkout completion rate/cart abandonment
Retention & loyalty
Repeat purchase rate
Purchase frequency
Customer lifetime value (LTV) or LTV proxy (cohort revenue over time)
CDGOs are expected to (1) choose the right scoreboard for the business model, (2) define clear metric ownership and targets, and (3) build the digital capabilities—product, data, platforms, experimentation—that consistently move those numbers.
Where CDGOs Sit in the Org (and what that means for scope)
The CDGO title is the same, but the scope changes dramatically depending on where the role sits in the organization. The fastest way to understand what a CDGO will actually do is to ask: Are they building the growth engine from scratch, scaling it, or governing it across a complex enterprise?
Startup CDGO
In a startup, the CDGO role is usually broad, hands-on, and close to the work, because the “digital growth engine” is still being assembled.
The scope typically entails:
End-to-end ownership across product, growth loops, measurement, and channel performance.
Hands-on leadership in experimentation, onboarding/activation, and conversion improvements.
Tight iteration with founders; faster decisions, fewer governance layers.
Compensation often includes meaningful equity upside, because impact is directly tied to business outcomes.
Fast-growth (Scaleup) CDGO
In a fast-growth org, CDGO becomes a system builder: creating repeatable growth mechanics and scaling the platform and teams that sustain them.
The job commonly includes:
Building an experimentation engine (process, tooling, cadence, and decision rules).
Converting “growth ideas” into a managed portfolio with clear ROI logic.
Aligning product, engineering, marketing, and RevOps around a shared KPI tree and operating rhythm.
Enterprise Chief Digital Growth Officer
In an enterprise, CDGO scope tends to shift toward portfolio governance + transformation at scale, with heavier stakeholder complexity and more formal accountability.
The scope typically revolves around:
Leading large-scale digital transformation across business units and functions.
Owning or influencing digital P&L and investment decisions (what gets funded, why, and what “good” looks like).
Driving standardized measurement discipline (consistent KPIs, dashboards, reporting, and accountability).
A concrete enterprise example of how broad the scope can be is at Church & Dwight, where the Chief Digital Growth Officer role has been described as heading digital transformation, owning P&L across eCommerce, and overseeing digital strategy, media, and measurement as part of the CEO’s executive leadership team.
Career Path: How Tech/Product/Digital Transformation Leaders Become CDGOs
If you’re coming from technology, product, or transformation, the move into CDGO is less about “becoming a marketer” and more about expanding your scope from delivery to growth ownership. The strongest CDGO candidates can show two things at once:
They can build and scale digital systems, and
They can tie those systems to measurable business outcomes with executive-level clarity.
Typical Feeder Roles
Head of Digital/Digital Director
This is often the most direct path. You already operate cross-functionally, own a digital roadmap, and influence customer experience. The CDGO step is taking full accountability for growth KPIs and not just transformation outputs.
VP Product/Product Director (with platform + analytics depth)
A strong feeder path where you’ve led product strategy tied to growth outcomes (activation, retention, conversion) and you understand measurement and experimentation as systems, not ad-hoc tactics.
CTO/VP Engineering (with strong business alignment)
This path works best when you’ve moved beyond “build what’s asked” into “shape what matters.” We are talking about portfolio prioritization, ROI trade-offs, platform decisions tied to revenue/efficiency, and exec influence. The CDGO step is owning the growth scoreboard and orchestrating across product, marketing, RevOps, and finance.
Transformation leader with measurable growth outcomes
Many CDGOs come from enterprise transformation roles, especially if they can prove the transformation produced business lift (e.g., digital revenue mix, conversion, cost-to-serve reductions), not just “modernized architecture.”
Now, it’s only reasonable to believe that some skills are still missing, regardless of the scope of the previous role. Let’s now see what those gaps are and how to bridge them.
The Skill Gaps That Block the Jump (and how to prove you have them)
Moving into CDGO isn’t about learning a new title. It’s more about demonstrating new executive muscles. Here’s the clean mapping employers look for: gap → proof artifact.
1) Commercial fluency → “I speak growth in business terms.”
Proof artifacts:
A one-page growth thesis (what drives revenue/retention and why).
A simple KPI tree linking product/digital initiatives to business outcomes.
Written trade-offs: what you won’t do and why.
2) Financial framing → “I can justify investment like an executive.”
Proof artifacts:
Two to three investment cases with costs, expected lift, and risks.
A before/after view of unit economics (LTV, CAC, margin, payback).
A quarterly portfolio allocation (run/grow/transform) with ROI logic.
3) Growth modeling → “I can quantify impact and forecast.”
Proof artifacts:
A lightweight growth model (inputs → outputs → scenarios).
Cohort analysis showing what changed and how you know.
Forecast assumptions and how you validated them (not perfect accuracy—credible logic).
4) Stakeholder influence → “I can align a leadership team and land decisions.”
Proof artifacts:
An exec-ready narrative memo (problem → plan → metrics → asks).
A stakeholder map with a cadence of decisions (who decides what, when).
A real example of cross-functional alignment (product/eng/marketing/finance) around shared KPIs.
5) Governance maturity → “I can scale growth without breaking trust.”
Proof artifacts:
A governance one-pager: guardrails for privacy, security, data quality, and experimentation.
KPI definitions + data lineage basics (what’s counted, where it comes from).
A release/experiment policy that balances speed with risk.
Key takeaway:
The CDGO promotion happens when you stop being evaluated on “delivery excellence” alone and start being trusted to run a growth operating system—strategy, portfolio, measurement, and cross-functional execution—with executive-grade clarity.
What Employers Look for in CDGO Candidates (signals & artifacts)
The hiring is rarely about titles on a CV. It’s about proof that you can own a growth scoreboard, build the digital system behind it, and align the organization to execute. Employers look for clear signals, and they expect you to back them up with artifacts that show how you think and operate.
3 Main Signals Employers Screen For
#1: You’ve owned a growth metric (not just contributed to one).
They want evidence you were accountable for movement in a KPI that matters—conversion, retention, activation, digital revenue mix, CAC efficiency, NRR—plus the ability to explain why it moved and what you changed.
#2: You’ve led a cross-functional portfolio (not a single project).
CDGO is portfolio leadership: balancing acquisition vs. retention, platform investments vs. quick wins, and sequencing work to compound impact. Strong candidates, therefore, show they’ve managed trade-offs across product, engineering, data, marketing/RevOps, and finance.
#3: You’ve built measurement discipline (and fought for clarity).
Employers want leaders who can define metrics, instrument the system, and create decision cadence. In other words, “We made a dashboard” just won’t cut it. You need to show them proof that you created a loop in which measurement changes prioritize.
Artifacts to Show (bring these to interviews)
These are “executive-grade” artifacts that instantly separate CDGO-ready candidates from senior functional leaders:
One-page strategy: your growth thesis, key bets, and what success looks like (in metrics).
KPI tree: north star → driver metrics → team-level levers (with definitions).
Experiment system: how hypotheses are generated, tested, reviewed, and scaled (and how you prevent noise).
Transformation roadmap: a sequenced plan that connects platform/data/product capability to measurable outcomes.
Operating model diagram: who owns what, decision rights, cadence, and governance (how the machine runs).
If you can show one real version of each (even simplified), you’ll answer most interview concerns before they’re asked.
The CDGO Interview Loop (what to expect)
Most CDGO loops test three things: strategy, execution orchestration, and measurement literacy. So, expect a process like:
1. Strategy case: “Here’s the business model and constraints. Where do you find growth, and what do you do first?”
They’re looking for:
Prioritization logic
Sequencing
A clear KPI tree
2. Stakeholder scenario: “Marketing wants X, product wants Y, finance wants cuts. What do you do?”
They’re looking for:
Influence
Trade-off framing
Decision clarity
Executive communication
3. Metrics deep-dive: “Show us how you measure growth, attribute impact, and decide what to scale.”
They’re looking for:
Rigor
Causal thinking
Clean definitions
Ability to tie metrics to action
4. 90-day plan: “If you started Monday, what would you do in the first 30/60/90 days?”
They’re looking for:
Diagnosis
Operating cadence
Quick wins vs foundational work
Governance
Remember this pattern: CDGO interviews are less about “what you built” and more about how you run the growth system—from strategy to measurement to cross-functional execution.
Compensation is highly scope-dependent. Two people can share the same title while owning very different mandates. It can be anything from “build the digital growth engine hands-on” to “run an enterprise-wide portfolio with P&L responsibility.” So use the benchmarks below as directional ranges, then adjust based on: business model, remit (P&L vs influence), team size, and whether the role is closer to CDO (transformation) or CGO (growth) in practice.
What Influences a CDGO Salary (and why ranges vary so much)
Scope & mandate: “owning outcomes” (growth KPIs) pays differently than “advising” on digital initiatives.
P&L responsibility: direct ownership of eCommerce/digital P&L typically increases base + bonus potential.
Company stage: startups skew toward equity/variable; enterprises skew toward higher base + structured bonus.
Team size & complexity: more functions/budget under you (or multiple business units) usually means higher comp.
Sector & regulation: finance/health/regulated industries often pay a premium due to governance and risk load.
Location: London vs non-London in the UK, and SF/NYC/Seattle vs other US markets can materially shift offers.
Role “lean”: CDGO roles closer to CDO (transformation) vs closer to CGO (growth/P&L) benchmark differently.
UK Salary Benchmark (based on scarce direct datapoints)
UK data for the exact CDGO title is scarce, which is why the Adria Solutions Salary 2026 Guide is unusually useful. Their benchmark lists the Chief Digital Growth Officer at approximately:
£80k (lower reference)
£90k (mid)
£110k+ (senior/upper)
Treat this as a baseline for UK market conversations, then adjust up or down based on London vs non-London, seniority, and whether the role carries P&L accountability.
US Ranges (how to benchmark when “CDGO” data is thin)
In the US, “Chief Digital Growth Officer” is still a relatively rare standardized title, so compensation is usually priced as a CDO/CGO hybrid. This means that employers often benchmark against Chief Digital Officer and Chief Growth Officer ranges, then calibrate based on scope.
Useful anchors (base-pay oriented; varies by data source and sample):
Chief Digital Officer (US): typical range roughly $245k–$454k (Glassdoor), and Salary.com estimates an average of around $299k. (Glassdoor)
Chief Growth Officer (US):Salary.com reports a typical range around $307k–$365k, while Glassdoor reports a wider (and often higher) band of roughly $369k–$678k.
How to translate this into a practical CDGO expectation:
Startup: base is often lower relative to enterprise, but compensation can skew toward upside (equity/variable), especially if the CDGO is building the system hands-on.
Fast-growth: tends to price toward the middle-to-upper end of the hybrid range when the CDGO owns a clear growth scoreboard plus platform/measurement leadership.
Enterprise: typically higher base + structured bonus, especially when scope includes eCommerce/digital P&L, enterprise-wide measurement, and multi-stakeholder governance.
Rule of thumb (for candidates): If the role is predominantly digital transformation (CDO-leaning), expect closer-to-CDO benchmarks. If it’s predominantly revenue growth ownership (CGO-leaning), expect closer-to-CGO benchmarks. Then add complexity premiums for P&L accountability and large-scale governance.
If you’re already senior and need commercial fluency to justify scope, comp, and mandate at CDGO level, the Digital MBA for Technology Leaders is designed to strengthen that executive readiness.
A CDGO’s first 90 days should prove one thing: you can turn “digital growth” into a repeatable operating system with a clear scoreboard, aligned stakeholders, and a portfolio that compounds impact.
This template is designed to be practical: you can copy it into your onboarding doc, adapt the language, and use it to structure your early wins.
Day 0–30: Diagnose, define the scoreboard, align the room
Primary goal: establish clarity and credibility fast. Define: what growth means here, how it’s measured, and where the constraints really are.
Action steps:
Run a structured diagnosis: current growth levers, bottlenecks, customer friction, platform constraints, data quality, and org dynamics.
Build a KPI tree: pick (or validate) the north star metric and define the drivers that teams can actually influence.
Map stakeholders and decision rights: who owns what, who blocks what, and what decisions need a cadence.
Identify “fast credibility wins”: 2–3 improvements that are safe, measurable, and quick to deliver.
Deliverables by Day 30
A one-page growth diagnosis memo (what’s happening + why).
A validated KPI tree with definitions and owners.
A stakeholder map + decision cadence proposal (weekly/monthly/quarterly).
A shortlist of top constraints (platform, process, data) with impact estimates.
Day 31–60: Reset the portfolio, fix measurement, build the experiment pipeline
Primary goal: move from diagnosis to execution; i.e., turn insights into a prioritized portfolio and a working growth loop.
Action steps
Portfolio reset: reprioritize initiatives based on impact, confidence, effort, and dependencies (not politics).
Install measurement discipline: align on metric definitions, fix instrumentation, and establish a single source of truth for key KPIs.
Create the experiment pipeline: a consistent system for hypotheses, prioritization, test design, and decision rules (scale/iterate/stop).
Stabilize delivery risks: remove bottlenecks, clarify platform roadmap dependencies, and address data quality issues that block learning.
Align teams on the cadence: weekly growth review + experiment review; monthly portfolio review.
Deliverables by Day 60
A sequenced growth portfolio roadmap (next 6–12 weeks) tied to KPIs.
A working measurement baseline (dashboards people trust).
An experiment backlog with clear hypotheses, success metrics, and owners.
A documented decision cadence (what gets reviewed, when, by whom).
Day 61–90: Scale what works, formalize the operating model, secure investment
Primary goal: prove repeatability; i.e., scale winning loops, institutionalize the cadence, and fund the capabilities that compound growth.
Action steps
Scale the winning loops: roll successful experiments into product/platform defaults (and document learnings).
Upgrade the operating model: clarify ownership boundaries across product, engineering, marketing, RevOps, and finance; tighten decision rights.
Build capability plans: what must be built (platform/data/automation), who must be hired, and what must be retired.
Create executive-ready investment cases: link capability investments to expected lift, cost, risk, and timeframe.
Set the next-quarter strategy: define the 2–4 bets that will drive growth and the leading indicators you’ll monitor.
Deliverables by Day 90
A set of scaled growth improvements tied to KPI movement.
An explicit growth operating model (ownership + cadence + governance).
2–3 board-ready investment cases with ROI logic and risk controls.
A quarterly strategy + OKR/KPI plan that leadership can rally around.
What “Good” Looks Like After 90 Days
By Day 90, the goal isn’t to “transform everything.” It’s to establish a machine:
A clear scoreboard that everyone trusts.
A portfolio aligned to that scoreboard.
A cadence that turns metrics into decisions.
And an operating model that scales learning into repeatable growth.
If you want a structured path to build these skills (and apply them immediately), the Digital MBA for Technology Leaders provides a guided framework to develop the executive toolkit behind that 90-day operating cadence.
How CTO Academy’s Digital MBA Maps to the CDGO Capability Stack
The fastest way to become “CDGO-ready” from a technology/product/transformation background is to close the threeexecutive gaps that block growth accountability:
Commercial fluency,
Strategic decision-making,
and Cross-functional alignment.
CTO Academy’s Digital MBA for Technology Leaders is explicitly positioned to build exactly those capabilities—moving senior tech leaders beyond operational delivery into commercial fluency, strategic vision, and stakeholder alignment.
CDGO competency: You can frame growth in business terms (unit economics, ROI, investment logic) and defend trade-offs at the exec/board level.
Digital MBA outcome: The program explicitly targets executive readiness and strengthening of financial and organizational acumen to drive growth, so you can translate digital initiatives into business value, budgets, and investment decisions.
CDGO competency: You can align product, engineering, marketing/RevOps, and finance around a shared scoreboard; then land decisions fast.
Digital MBA outcome: The program is framed around building strategic impact and improving your ability to bridge communication between technical and non-technical stakeholders, which is a core CDGO requirement.
3) Operating cadence & governance mindset → The “exec operating system” for tech leaders
CDGO competency: You can run the growth machine: weekly metrics reviews, monthly portfolio decisions, quarterly investment cases without losing control (risk, governance, accountability).
Digital MBA outcome: This is a structured executive program with a clear curriculum and format, designed to give experienced tech leaders the executive tools and operating patterns to lead confidently at a senior level; i.e., an executive-grade operating system rather than a set of disconnected lessons.
Are You a Strong Program Candidate (checklist)
This mapping is strongest for tech/product leaders moving from delivery → growth accountability, for example:
Heads of Digital and transformation leaders who want a direct line from initiatives to growth outcomes.
Product/platform leaders who want stronger executive influence and commercial framing.
CTOs/VPs of Engineering who want to own the growth scoreboard (not just execution quality).
If you’re bridging tech leadership into growth ownership, CTO Academy’s Digital MBA is built around the exact shift a CDGO must make: from operational excellence to executive-grade commercial impact and alignment.
CDGO Checklist (Are you effectively doing the CDGO job already?)
If your role consistently includes most of the points below, you’re operating as a Chief Digital Growth Officer (CDGO) in practice, whether or not you have the title:
You’re accountable for growth outcomes (revenue, retention, conversion, efficiency), not just delivery metrics.
You run a growth cadence (weekly KPI reviews, experiment reviews; monthly portfolio reprioritization; quarterly investment/strategy refresh).
You own or heavily influence the digital system behind growth: product experience, platform roadmap, instrumentation, analytics, and experimentation.
You build and maintain a KPI tree that ties initiatives to business outcomes, and you use it to make trade-offs.
You lead a cross-functional portfolio (product, engineering, marketing/RevOps, finance), aligning teams around one scoreboard.
You produce executive-grade artifacts (one-page strategy, forecasts, investment cases) that win decisions and funding.
You enforce measurement discipline (clear definitions, trusted dashboards, data quality) so performance drives prioritization.
You balance speed with governance and risk (privacy, security, compliance guardrails) so growth scales safely.
Key Takeaways
CDGO is the “growth-through-digital-systems” executive. The role blends the transformation strengths of a CDO with the outcome ownership of a CGO, operationalizing it through platforms, data, and cadence.
The mandate is stable across companies: own the growth scoreboard, build the digital system behind it, align cross-functional execution, and scale safely with governance (privacy, security, compliance).
Employers hire for proof, not titles. The strongest candidates show a moved growth metric, a managed cross-functional portfolio, and a credible measurement discipline backed by artifacts (KPI tree, one-page strategy, experiment system, operating model).
Your first 90 days should be spent installing the machine. Diagnose + KPI tree + stakeholder map (0–30), portfolio reset + measurement + experiment pipeline (31–60), then scale loops + operating model + investment cases (61–90).
For tech/product/transformation leaders, the biggest jump is executive capability. Commercial fluency, financial framing, growth modeling, stakeholder influence, and governance maturity are the differences between “senior leader” and “CDGO-ready.”
Conclusion
CDGO is a natural next step for tech and product leaders who want to move from building systems to owning outcomes, and who enjoy turning growth into a repeatable operating discipline rather than a collection of initiatives.
If your ambition is to sit closer to portfolio decisions, unit economics, and executive alignment—without abandoning the leverage of technology—CDGO is one of the cleanest modern pathways to do it.
Frequently Asked Questions (FAQ)
What does a Chief Digital Growth Officer do?
A Chief Digital Growth Officer (CDGO) is a C-suite leader accountable for measurable growth outcomes (revenue, retention, conversion, efficiency) by building and improving the digital systems that drive them: product experience, data/analytics, platforms, experimentation, and the cross-functional operating model that turns insights into execution.
CDGO vs CDO vs CGO: what’s the difference?
A CDO (Chief Digital Officer) typically focuses on digital strategy and transformation, modernizing the business and customer experience through digital capabilities. A CGO (Chief Growth Officer) focuses on growth strategy across functions, coordinating efforts to increase revenue and expansion. A CDGO blends both: they own growth outcomes and deliver them through a digital operating system (platform + data + experimentation + cross-functional cadence), often functioning as a CDO/CGO hybrid.
How do I become a CDGO from a CTO/VP Engineering background?
You become CDGO-ready by expanding from delivery excellence into growth accountability. Concretely: (1) Pick and own a growth metric (e.g., conversion, activation, retention) and demonstrate movement. (2) Build a KPI tree that links platform/product work to business outcomes. (3) Run a cross-functional portfolio (product, marketing/RevOps, finance) with an operating cadence. (4) Develop financial framing (ROI, payback, unit economics) for investment decisions. (5) Prove governance maturity (privacy/security/data quality) so growth scales safely.
What KPIs does a CDGO own?
It depends on the business model, but most CDGOs own a mix of outcomes and efficiency: revenue growth, conversion/activation, retention, and unit economics (LTV, CAC, payback). In eCommerce, that often means digital revenue mix, conversion rate, AOV, and repeat rate. In SaaS, it’s activation, retention, net revenue retention (NRR), expansion, and CAC payback. In marketplaces, it’s liquidity (supply-demand match), take rate, and cohort health.
What salary should a CDGO expect in the UK?
UK benchmarks for the exact “Chief Digital Growth Officer” title are rare, but Adria Solutions’ Salary 2026 Guide lists CDGO roughly around £80k (lower reference), £90k (mid), and £110k+ (upper). Actual offers vary by scope (P&L accountability vs influence), London vs non-London, and whether the role leans more “CDO” (transformation) or “CGO” (growth ownership).
Is CDGO a real role or just a renamed CDO/CGO?
It’s a real role that’s appearing as companies merge “digital transformation” with “growth accountability.” In some organizations, it is effectively a renamed CDO or CGO, but the defining signal of a true CDGO is this: they own a growth scoreboard and have the mandate to build the digital systems and cross-functional operating model needed to move it.
What’s the fastest way to tell if a CDGO role is “real” (and not just a title)?
Look for three things in the job scope: (1) Explicit ownership of growth outcomes (revenue, retention, conversion, efficiency) (2) Ownership/influence over digital systems (platform roadmap, data/measurement, experimentation) (3) Authority to orchestrate across functions (product/engineering/marketing/RevOps/finance) with a formal operating cadence.
Do CDGOs typically own P&L?
Sometimes. In scaleups and enterprises, some CDGOs own digital or eCommerce P&L directly; in other orgs, they “own the numbers” without formal P&L ownership by controlling the growth levers and investment portfolio. The more direct the P&L accountability is, the more the role behaves like an executive growth operator rather than a transformation leader.
How to move from IT Manager to IT Director across software-first and asset-heavy industries.
Most people describe the IT Director as if it’s a software organization role: backlogs, agile rituals, dev velocity, maybe a bit of cloud. In reality, the hardest IT Director jobs are often in places where software isn’t the product, yet downtime, compliance, and security are existential.
Think manufacturing, where a “minor” network change stalls a production line. Healthcare, where access controls are patient safety. Logistics, where a failed integration becomes a revenue event. Or financial services, where audit findings can freeze initiatives overnight. In these environments, the IT Director isn’t optimizing features; they’re balancing operational continuity, regulated risk, vendor ecosystems, and human behavior. And doing all of that while being held accountable for outcomes they don’t fully control.
This guide gives you a clear, field-tested definition of the modern IT Director role, plus real-world examples of what “good” looks like when priorities collide. Most importantly, you’ll get an IT Director Readiness Scorecard based on our 9-signal model so you can assess where you’re strong, where you’re exposed, and what to fix next, before the role (or an incident) forces the lesson.
Now, to address your more immediate predicament: Why should you trust and use this guide?
CTO Academy was founded in 2019 to help technology leaders move beyond technical execution and lead with board-level commercial confidence.
Today, we support technology leaders in 100+ countries and have worked with thousands of tech leaders across a wide range of organizations.
This article reflects patterns we see repeatedly in:
The Digital MBA for Technology Leaders, where the learning experience is continuously stress-tested in practice (including weekly Q&A sessions)
In-person meetups and networking events, hosted across multiple cities either directly by our senior leadership team or through our local Chapter Directors.
We also publish our learning openly: CTO Academy’s Digital MBA has amassed 50,000+ individual lecture reviews so far, and we’re rated 4.9/5 on Trustpilot with 161 reviews.
The toughest IT Director roles aren’t “software org” roles—they’re in manufacturing, healthcare, retail, and public sector environments where downtime, compliance, and security are existential.
“Runs IT” doesn’t mean “runs tickets.” Directors own outcomes: availability, security, cost control, service levels, and risk posture—and they design the operating system (people + process + vendors + governance) that produces those outcomes.
Hiring managers evaluate you using 9 signals (even if they don’t say it): operational ownership, risk-based prioritization, security-by-design, incident leadership, vendor command, financial discipline, service model clarity, change governance, and executive alignment.
The IT Director Readiness Scorecard lets you self-assess in ~10 minutes and identify the lowest 2–3 signals to upgrade first.
Use the 30–60–90 plan to close gaps fast (e.g., finance, security, stakeholder alignment) and assemble a director interview “proof pack” (roadmap, risk register, budget narrative, service catalog/SLAs, postmortem).
Bottom line: IT Director is a system role, not a seniority badge. Build the system, bring proof, and you’ll be trusted with the title.
Table of Contents
Get the IT Career Path Roadmap (Free PDF)
Want more than scattered ideas? Get our IT Career Path Roadmap PDF – an 8-step framework to map your next roles, sharpen your skills, and build a layoff-resilient tech leadership career. Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
An IT Director is accountable for business outcomes—availability, security, cost control, service levels, and risk posture—by designing and running the operating model (people, process, vendors, and governance) that makes those outcomes repeatable.
In plain English: you don’t just “run IT.” You build the system that prevents surprises—and you can prove it with evidence.
What an IT Director owns (even when others execute):
Availability: critical services stay reliable, and downtime is managed like a business event.
Security: controls are operationalized, incidents are handled decisively, and compliance is provable.
Cost control: spend is intentional, forecastable, and explained in business language.
Service levels: expectations are defined, measured, and improved with a clear service model.
Risk posture: leadership can see tradeoffs, accept/avoid risk knowingly, and track mitigation.
The IT Director Role Exists Far Beyond “Software-first”
If your mental model of an IT Director is “runs the internal dev org,” you’ll miss where the role is most intense: environments where tech is mission-critical but not necessarily the product itself. The title shows up anywhere operations, regulation, and security collide, and where the business expects stability and change at the same time.
Manufacturing (OT + IT)
In manufacturing, the scariest incidents don’t start with servers but with stopped lines.
A ransomware scare or a single misconfigured switch can cascade into production downtime, missed shipments, and contractual penalties.
The IT Director sits between OT engineers, plant leadership, and vendors who “need remote access right now.” The work is unglamorous and high-stakes:
Network segmentation between OT and corporate IT.
Disciplined patch windows that respect production schedules.
Clear escalation paths when safety and uptime compete.
Healthcare
In healthcare, IT is inseparable from patient safety and privacy law.
When the EHR slows or goes down, clinicians lose time, and outcomes can be affected. When identity controls fail, breaches become a reputational and regulatory crisis.
The IT Director’s world, therefore, revolves around:
In this environment, “security” isn’t a department but a set of controls embedded into onboarding, clinical workflows, and vendor integrations, without breaking care delivery.
Retail/Hospitality
Retail and hospitality run on transactions and peak moments. If stores lose connectivity, POS stalls, inventory accuracy degrades, and revenue evaporates in real time.
The IT Director is effectively running a distributed operations platform:
Store networks
Redundancy
Device fleet management (POS, kiosks, handhelds)
Vendor SLAs that actually hold during chaos.
Peak season planning becomes its own discipline: capacity, incident playbooks, staged rollouts, and change freezes that balance resilience with the reality that the business can’t pause growth.
Public Sector/Utilities
Public sector and utilities carry a unique mix: legacy systems, procurement constraints, and compliance. Often, the infrastructure cannot simply be replaced.
So the IT Director has to:
Sequence modernization without breaking core services.
Navigate procurement timelines that outlast technologies.
Make risk acceptance explicit when “perfect” isn’t possible.
This is where governance is operational: documentation, controls, stakeholder alignment, and the ability to explain tradeoffs to leadership in plain language, because accountability doesn’t disappear just because the stack is old.
Across these sectors, the title changes less than the constraints. The core job is universal: keep critical services reliable, reduce risk, control spend, and make change safe. But the shape of the work depends on what the business is made of. In software-first companies, pressure often comes from speed, scale, and platform complexity. In asset-heavy and regulated environments, pressure comes from uptime, safety, vendor ecosystems, legacy, and compliance that can’t be negotiated away.
In other words, the IT Director role travels. The context shifts, but the accountability doesn’t. And that’s what we’ll define next.
➡️ See where you’d be hired today vs. promoted later.
What an IT Director is Actually Accountable For (in plain language)
An IT Director isn’t measured by how many projects move forward or how quickly tickets get closed. They’re measured by whether the business can operate safely, reliably, and predictably, even when priorities conflict.
IT Director’s Key Accountabilities
Here’s what that accountability looks like in outcomes (not tasks):
Availability:
Critical systems stay up
Performance is stable
Recovery is fast when things break.
Security:
The organization reduces real exposure (identity, endpoints, vendor access, data), responds decisively to incidents, and proves controls under scrutiny.
Cost control:
Spend is intentional: licenses, cloud, vendors, and hardware are optimized without creating hidden risk or operational debt.
Service levels:
The business gets consistent, measurable support: clear expectations, transparent performance, and fewer “surprise outages.”
Risk posture:
Leadership understands what’s acceptable, what’s not, and what’s being done about it; all backed by evidence, not optimism.
That’s why “runs IT” does not mean “runs tickets.” Directors don’t just manage work; they design the operating system that makes reliable work possible:
Org structure
Decision rules
Escalation paths
Vendor model
Governance cadence
Metrics that tell the truth
In short, they build a system where priorities are explicit, changes are controlled, and accountability is shared across IT, security, finance, and the business.
IT Director vs IT Manager (Role Boundary)
At this point, you might be wondering about the difference between the IT Manager and IT Director roles. Here is the simplest way to differentiate between these two:
Owns team throughput, ticket flow, project delivery coordination, and operational follow-through.
IT Director owns outcomes, prioritization, governance, and cross-functional alignment:
Sets priorities, defines service expectations, manages risk tradeoffs, holds vendors accountable, and ensures IT decisions match business reality.
Here’s the visual presentation of the role differences:
Differences between the IT Director and IT Manager roles
If you’re nodding along to the role boundary above, here’s the key shift:
The IT Manager role rewards execution.
The IT Director role rewards evidence of outcomes.
It’s the reason why most interviewers won’t just ask, “Can you own availability, risk, and spend across the business?” Instead, they’ll probe around the edges: how do you decide, govern, handle vendors, respond when things break, and, more importantly, whether leaders trust your tradeoffs.
That’s why the next section matters. These are the patterns hiring managers look for—often unconsciously—when they’re deciding whether someone can carry director-level accountability.
9 Signals Hiring Managers Use
Hiring managers rarely say, “We need someone who can carry director-level accountability.” They describe symptoms instead: firefighting, fragile vendors, unclear priorities, rising risk, ballooning spend, and stalled modernization.
These are the nine signals that predict whether someone can carry director-level accountability, before the title forces the learning curve (Columns: Signal → Meaning → KPI examples):
Signal
Meaning
KPI examples
Signal 1: Operational ownership
You reliably keep critical services stable, not just “manage the queue.”
• Uptime/SLA (or SLO) attainment • MTTR by severity (and repeat-incident rate) • Backup test success rate/patch compliance (critical tiers)
Signal 2: Risk-based prioritization
You can defend tradeoffs with impact, not opinions.
• # top risks with owner + ETA (and % with treatment plan) • % roadmap work mapped to business-critical services/risks • Time-to-decision for risk acceptance/mitigation
Signal 3: Security-by-design
Identity, access, and controls are built into operations (not bolted on after incidents).
• MFA coverage/privileged access review completion • EDR + encryption coverage • Vulnerability remediation time by severity
Signal 4: Incident leadership
You lead response calmly, coordinate cross-functionally, and drive postmortems into real change.
• MTTD/MTTA and time-to-stabilize • % major incidents with postmortem completed on time • % postmortem action items closed by due date
Signal 5: Vendor command
You control vendors with contracts, SLAs, and governance (not hope and escalations).
You manage total cost, eliminate waste, and explain spending in business language.
• Budget variance/run-rate forecast accuracy • License utilization rate (waste removed) • Cost per user/endpoint/site (trend over time)
Signal 7: Service model clarity
You define “what IT provides,” how it’s requested, and what good looks like.
• First response time/resolution time by priority • % tickets meeting SLA (and reopen rate) • Service satisfaction (CSAT or stakeholder score)
Signal 8: Change governance
You reduce chaos with release discipline, standards, and measurable reliability.
• Change failure rate/rollback rate • Incidents caused by change (and emergency changes %) • % changes with documented risk + rollback plan
Signal 9: Executive alignment
You translate tech reality into business decisions leaders will own.
You translate tech reality into business decisions that leaders will own.
Don’t worry; you’ll score yourself in 10 minutes below.
The IT Director Readiness Scorecard (based on the 9-signal model)
Use this scorecard to measure whether you’re operating at director-level accountability today, or still building the system that makes those outcomes possible.
How to use it (~10 minutes)
Read each signal and answer the question based on your current reality, not intent.
Score yourself 0–3 using the rubric below.
Add up your points (max 27).
Use the interpretation bands to pick the next moves that close the biggest gaps.
Scoring rubric (0–3)
0 — Not demonstrated: No consistent examples. Mostly ad hoc, reactive, or owned by someone else.
1 — Emerging: You’ve done parts of it, but it’s inconsistent, personality-dependent, or limited to one area/team.
2 — Proven: You can show repeatable results. There’s a process, evidence, and stakeholder trust.
3 — Director-ready: You’ve built a durable system that scales (people + process + vendors + governance) and survives complexity.
If a critical service fails, do you already have clear owners, monitoring, on-call/escalation, and measurable targets (uptime/MTTR), and can you prove improvement over time?
2) Risk-based prioritization
Can you explain why your top priorities are the top priorities using impact and risk (revenue, safety, compliance, downtime), and get cross-functional buy-in?
3) Security-by-design
Are identity, access control (MFA/PAM), endpoint standards, and vendor access governed by default without needing a security “clean-up project” every quarter?
4) Incident leadership
When incidents happen, do you lead coordination calmly, communicate clearly to stakeholders, and run postmortems that result in tracked fixes—not repeat failures?
5) Vendor command
Do you manage vendors through contracts/SLAs, regular governance, and measurable performance, so outcomes don’t depend on escalation drama?
6) Financial discipline
Can you defend and optimize IT spend (licenses, cloud, vendors, hardware) with visibility into unit costs and waste without degrading reliability or security?
7) Service model clarity
Is it obvious to the business what IT provides, how to request it, what “good” looks like (SLAs), and what’s out of scope (i.e., reducing chaos and surprises)?
8) Change governance
Do you have release/change controls (standards, CAB/lightweight approvals, maintenance windows, rollback) that reduce risk while still enabling progress?
9) Executive alignment
Can you translate technical reality into decisions leaders own (tradeoffs, risk acceptance, timelines), and keep alignment even under pressure?
Total score (out of 27): _______
Interpreting your results (and what to do next)
0–9: Not yet hire-ready (high exposure)
You may be strong technically, but the operating system isn’t there yet. Focus on stability + control first: clarify ownership, basic service levels, incident response, and vendor access.
Action: pick two signals where failure would cause the biggest business harm (usually Operational Ownership + Security-by-design) and build a repeatable baseline.
10–17: Hireable in the right environment (needs support)
You can run meaningful parts of the director role, but consistency may depend on you personally rather than the system.
Action: systematize the work by defining service models, implementing lightweight governance, and building reporting that leadership understands (risk + cost + reliability). Your initial aim is to move 2–3 signals from “2” to “3.”
18–23: Strong director-ready (scales beyond you)
You’re already operating at the director level in most areas. The gap is usually scaled: more stakeholders, more vendors, more compliance, more consequences.
Action: sharpen executive alignment and financial storytelling, strengthen vendor governance, and formalize risk acceptance. This is where you become the person who can inherit messy environments.
24–27: Promotion-ready/enterprise-grade
You’re building durable systems, and you can carry accountability across complexity.
Action: broaden your scope -> multi-site resilience, deeper security governance, modernization sequencing, and leadership development (bench strength). Start documenting your “operating model” as part of your leadership narrative.
Tip: Your fastest improvement comes from the lowest-scoring signal that creates the most downstream failures (often Vendor Command, Change Governance, or Executive Alignment).
Practical 30–60–90 Day Upskilling Plan (closing gaps)
Don’t “improve everything.” Instead, pick your lowest 2–3 signals and run a focused 30–60–90 so you can show director-level progress with evidence (not vibes). Below are three common gap patterns and exactly what to do.
If you’re weak in Finance (Financial discipline)
You want to move from “we spend what we spend” to explainable, optimizable costs tied to outcomes.
Days 0–30: Visibility
Build a service cost model (simple is fine): top 10 vendors + licenses + cloud + hardware + key labor buckets.
Tag spend into 5–8 categories (Productivity, Core Infrastructure, Security, Line-of-business apps, Connectivity, etc.).
If you’re weak in Stakeholder alignment (Executive alignment + prioritization)
Replace reactive intake with a business-aligned roadmap and a cadence that leaders trust.
Days 0–30: Translate demand into decisions
Interview 6–10 stakeholders using the same questions: “Top 3 outcomes? Biggest risk? What breaks your day?”
Build a single prioritization framework (impact + risk + urgency + effort) and apply it publicly.
Publish an “Intake → Decision” flow: what gets reviewed weekly vs. monthly, who decides, what info is required.
Days 31–60: Roadmap + expectations
Create a business-aligned roadmap (now/next/later) tied to outcomes (uptime, compliance, speed, cost).
Define service expectations: top services, SLAs, and what IT will stop doing (or do differently).
Start a monthly QBR cadence with a consistent agenda: reliability, risks, spend, progress, decisions needed.
Days 61–90: Lock in trust
Deliver 2–3 “credibility wins” from the roadmap (stability, vendor performance, or security control improvements).
Introduce a lightweight risk acceptance process for tradeoffs leaders must own.
Create a one-page exec update template (no tech jargon): status, wins, risks, asks.
Artifact-as-Proof:
Stakeholder notes
Roadmap
QBR deck
Decision log
Reduced escalations
Clearer priorities
How to choose your immediate 30–60–90
Take the lowest-scoring signal that causes the biggest downstream pain (usually Finance, Security, Vendor Command, or Executive Alignment).
Then commit to shipping artifacts every 30 days, because artifacts are what hiring managers recognize as “director-level.”
A structured path to the IT Director role
Now, it is clear that all of this isn’t something you can grasp overnight or just “google” it. It doesn’t work like that. What you need is a structured path that combines strategic, commercial, and leadership disciplines across nine interconnected modules — each designed to strengthen executive impact and prepare senior technology leaders for C-suite success.
Remember, the ultimate goal here is to move beyond operational delivery and lead with the board-level influence. Take a look:
Bridge the gap between tech and leadership.
Designed exclusively for ambitious technology leaders, the Digital MBA equips you with the tools, mentors, and network to scale your impact and transform from an experienced technologist into a confident, strategic leader.
The Director Interview “Proof Pack” (what to bring, what to say)
Most candidates try to tell hiring managers they’re ready. Director-level candidates show it.
The fastest way to stand out is to bring a small set of artifacts that prove you can own outcomes, run governance, and align the business without turning the interview into a theory lecture. Ideally, this should be about the org you’re applying to, but the portfolio examples (jobs from the past) will do as well.
However — and take this seriously — if there is time, you should absolutely do your due diligence and prep the materials from the perspective of an active IT Director of that particular organization. This additional effort will give a real competitive edge and make the rest of the candidates look like beginners. Don’t forget that the cover letter attached to your resume isn’t about you but the job you’re applying for.
This is what you need:
1) One-page IT strategy + prioritized roadmap
Bring: a single page with current state, 3–5 priorities, success metrics, and a “Now/Next/Later” roadmap.
Say: “Here’s how I translate business outcomes into a sequencing plan: what we do first, what we defer, and why.”
This way, you prove: prioritization, executive alignment, change governance, and operational ownership.
2) Risk register + top 10 mitigations
Bring: a risk register excerpt (sanitized) with likelihood/impact, owner, mitigation, due date, and status. The best practice is to include the top 10 mitigations you drove.
Say: “This is how I make risk visible and actionable. Decisions are explicit, owners are named, and progress is measurable.”
This proves the following signals: risk posture, security-by-design, executive alignment, and governance.
3) Budget narrative + savings levers
Bring: a 1–2 page budget narrative: spend categories, drivers, what’s non-negotiable, and 5–8 savings levers (with tradeoffs).
Say: “I don’t just cut costs—I manage cost and risk. Here’s what I’d optimize first and what I wouldn’t touch.”
Signals it proves: financial discipline, vendor command, prioritization, and stakeholder trust.
4) Service catalog + SLAs
Bring: a simple service catalog: what IT provides, request paths, SLAs/SLOs, and escalation.
Say: “This reduces chaos. The business knows what to expect, and IT knows what ‘good’ looks like.”
You will prove: service model clarity, operational ownership, and executive alignment.
5) Incident postmortem sample
Bring: a sanitized postmortem with timeline, impact, root cause(s), corrective actions, owners, and follow-up dates.
Say: “I lead incidents with calm, then turn lessons into system changes so we don’t repeat failures.”
This proves: incident leadership, change governance, operational ownership, and security maturity.
Once you have the proof pack, you’ve done the hard part: you can show how you operate. Now you need to walk the interviewer through it with stories that make the artifacts feel inevitable. You’re going to be talking about a clear situation, a clear tradeoff, and a clear outcome.
That’s where the STAR Method comes in. Use the prompts below to turn each signal into a tight narrative that connects what you brought (roadmap, risk register, postmortem, SLAs, budget) to what hiring managers actually hire for: director-level judgment, governance, and repeatable results.
IT Director Job Interview Questions (STAR story prompts tailored to each signal)
Use these prompts to prepare 1–2 strong stories per signal (keep them tight: Situation → Task → Action → Result, then “what I changed so it stays fixed”):
1) Operational ownership
“Tell me about a time you stabilized a fragile environment.”
“How did you improve uptime/MTTR, and what evidence did you use?”
2) Risk-based prioritization
“Describe a conflict where stakeholders wanted everything. How did you decide what came first?”
“What tradeoff did you defend, and how did you get buy-in?”
3) Security-by-design
“Share a time you reduced exposure through baseline controls (identity, endpoints, vendor access).”
“How did you implement controls without breaking operations?”
4) Incident leadership
“Walk me through your most serious incident: how did you coordinate, communicate, and recover?”
“What changes did you make afterward to prevent recurrence?”
5) Vendor command
“Tell me about a vendor that was underperforming. What did you change: SLAs, governance, escalation, contract terms?”
“How did you make vendor outcomes predictable?”
6) Financial discipline
“Give an example where you optimized spending without increasing risk.”
“How did you build a cost model or justify a budget with business language?”
7) Service model clarity
“Describe how you clarified what IT provides and set expectations (SLAs/SLOs).”
“What changed in ticket volume, escalations, or satisfaction afterward?”
8) Change governance
“Tell me about a time you reduced outages caused by change.”
“What controls did you implement (maintenance windows, approvals, rollback, standards) and how did you keep delivery moving?”
9) Executive alignment
“Describe a time you turned technical constraints into a decision leaders owned.”
“How did you handle risk acceptance and keep alignment under pressure?”
How to use the proof pack in the interview
Offer it early: “I brought a few one-page artifacts that show how I run outcomes. Happy to reference them as we talk.”
Keep it sanitized: remove company names, sensitive metrics, and exact configurations.
Tie each artifact to a result: “This changed X (uptime, audit findings, spend, incident frequency) over Y period.”
This is what hiring managers rarely get—and immediately recognize as director readiness.
Common Traps That Stall Promotions (and how to avoid them)
Being “the person who gets things done” is valuable, but it’s not the same as being the person who can own outcomes through a system. These traps keep strong IT managers and senior engineers from being trusted with director-level accountability.
Trap
What it looks like
Why does it stall promotions
How to avoid it (mitigation)
“Hero operator” trap
You’re the escalation path for everything. You fix incidents personally, unblock vendors, and keep the lights on through sheer effort. Leadership loves you until they realize the operation collapses when you’re away.
Director readiness is proven by outcomes that scale beyond you. If reliability depends on one person, leadership won’t trust you with broader accountability.
1) Build repeatability: defined owners, on-call/escalation, runbooks, monitoring, and postmortems with assigned actions + deadlines.
2) Track fewer repeat incidents and improved MTTR as proof.
Security-as-an-afterthought trap
Security work happens only after incidents, audits, or panic moments. Exceptions accumulate. Controls are bolted on late and inconsistently enforced.
Directors are expected to manage risk by default, not by reaction. “We’ll fix it next quarter” reads as unmanaged exposure.
2) Run a tabletop exercise and publish a simple posture update.
Vendor-led architecture trap
Vendors drive decisions. Tool sprawl increases, integrations are inconsistent, logging/identity are fragmented, and contracts lock you into poor outcomes.
Directors must own architecture decisions that protect uptime, cost, and control—not outsource strategy to sales cycles.
2) Create a rationalization plan: keep/consolidate/renegotiate/retire.
No governance/no cadence trap
Work arrives via pings and emergencies. Priorities shift weekly. There’s no consistent review of reliability, risk, spend, or vendor performance. Everything is just in constant motion.
Without governance, outcomes aren’t predictable. Directors create the operating cadence that turns chaos into managed tradeoffs.
1) Implement lightweight rhythms: weekly prioritization + change review, monthly service health + risk review, quarterly roadmap + vendor QBRs.
2) Maintain a decision log and publish a one-page exec update (status, risks, asks).
The common thread here is that promotions stall when your value is “I personally handle it.” Promotions accelerate when your value becomes “I built the system that handles it.” This is the essence of leadership: moving from an IC to a delegator.
Key Takeaways
The hardest IT Director roles aren’t “software-first.” They’re in environments where downtime, compliance, and security are existential, even when software isn’t the product.
“Runs IT” ≠ “runs tickets.” IT Directors are accountable for outcomes: availability, security, cost control, service levels, and risk posture.
Director readiness is about building the operating system (people + process + vendors + governance) that makes results repeatable without heroics.
Hiring managers evaluate you using 9 signals, whether or not they name them: operational ownership, risk-based prioritization, security-by-design, incident leadership, vendor command, financial discipline, service model clarity, change governance, and executive alignment.
The fastest path forward is targeted: score yourself, pick your lowest 2–3 signals, and run a 30–60–90 plan that produces visible artifacts and measurable progress.
Bring proof, not promises: a concise director “proof pack” (roadmap, risk register, budget narrative, service catalog/SLAs, postmortem) turns interviews into evidence-based conversations.
Avoid the traps that stall promotions: hero operator, security later, vendor-led architecture, and no governance cadence.
Your Next Move
The IT Director role isn’t a seniority badge. It’s a system role: you’re accountable for outcomes, and your job is to build the operating model (people, process, vendors, governance) that makes those outcomes repeatable under pressure.
If you take one thing from this guide, let it be this: promotions don’t happen when you’re the best problem-solver in the room. They happen when leaders trust you to reduce chaos, surface tradeoffs, and run IT like a business capability—with reliability, security, and cost control that stand up to scrutiny.
Your next move is simple:
Score yourself on the 9 signals.
Pick your lowest 2–3 and run the 30–60–90 plan.
Build your interview “proof pack,” so your readiness is visible in minutes and not argued over in interviews.
When you’re ready, take the Scorecard and see exactly where you’d be hired today vs. promoted later.
Frequently Asked Questions (FAQ)
What’s the difference between an IT Manager and an IT Director?
An IT Manager runs day-to-day execution (tickets, team throughput, operational follow-through). An IT Director owns business outcomes: availability, security, cost control, service levels, and risk posture. Directors design the operating system—people, process, vendors, governance—so outcomes are repeatable without heroics.
Do I need to come from a software company to become an IT Director?
No. Many of the hardest IT Director roles are in manufacturing, healthcare, retail/hospitality, and public sector—where software isn’t the product but downtime and compliance are existential. What matters is whether you can run outcomes and governance, not whether you’ve shipped product features.
How do hiring managers evaluate IT Director candidates (even if they don’t say it)?
They look for signals that you can carry director-level accountability: operational ownership, risk-based prioritization, security-by-design, incident leadership, vendor command, financial discipline, service model clarity, change governance, and executive alignment. These show up through your examples, your artifacts, and how you talk about tradeoffs.
What if I’ve never “owned a budget”? Can I still get an IT Director role?
Yes, but you need to demonstrate financial thinking. Build a simple service cost model (top vendors, licenses, cloud, hardware), identify waste, and propose savings levers with tradeoffs. In interviews, show you can explain spending in business language and connect cost decisions to risk and reliability.
How do I prove IT Director readiness in an interview?
Bring a small “proof pack” of artifacts (sanitized): a 1-page strategy + roadmap, risk register, budget narrative, service catalog + SLAs, and an incident postmortem sample. These instantly signal you operate at the director level—because you’re showing governance, prioritization, and outcomes, not just describing them.
What’s the fastest way to improve my score in the next 90 days?
Don’t try to level up everything. Pick your lowest 2–3 signals and run a focused 30–60–90 plan. The fastest compounding upgrades usually come from: Vendor command (SLAs + governance + rationalization) Change governance (fewer change-caused outages) Executive alignment (roadmap + decision cadence) Shipping artifacts every 30 days beats “working on it.”
I’m technically strong, but I keep getting passed over. Why?
Common reasons: you’re seen as a hero operator (systems depend on you), you treat security as “later,” vendors drive architecture, or there’s no governance cadence. Promotions happen when leaders trust you to reduce chaos through a system—clear priorities, measurable reliability, explicit risk decisions, and predictable delivery.
What score on the readiness scorecard is “good enough” to apply?
As a rough guide: 10–17: hireable in the right environment (with support) 18–23: strong director-ready 24–27: promotion-ready / enterprise-grade But scoring isn’t the point—closing the highest-impact gaps is. If your low scores are in security, vendor command, or executive alignment, address those first because they drive the most visible outcomes.
Most leadership candidates don’t have a skill gap but a signal gap. These are, effectively, patterns that down-rank you for Tech Lead/EM/Head roles.
In this quick guide, we’ll briefly explain the 7 most common mistakes and provide fixes that translate your work into scope, influence, and outcomes.
If your career map leads to senior technology leadership, this is how you want to tweak both your LinkedIn profile and resume.
But first, you need to understand what hiring managers look for when they browse through CVs or LinkedIn profiles.
The Leadership Signals Hiring Managers Scan For (quick context)
When a hiring manager opens your CV/LinkedIn, they’re not trying to confirm you can build. They’re scanning for leadership readiness or, in other words, signals that you can own outcomes, make good decisions under constraints, and align people to deliver.
4 Cues They Look For (often in the first 20 seconds):
Scope: What size problem did you own? (domain, platform, product area, budget/headcount, #services/regions/customers, etc.)
Judgment: What tradeoffs did you make, and why? (prioritization, risk, architecture, sequencing, build vs buy)
Influence: Who did you align, and how? (Product, Security, Legal, Finance, Sales, other engineering teams)
Outcomes: What changed because of your leadership? (speed, reliability, cost, revenue, risk reduction—ideally with a number)
If your profile is heavy on tools and tasks but light on these four signals, it can unintentionally read as “great engineer” rather than “ready to lead”—even if you’re already doing leadership work.
7 Mistakes with the Fixes
Mistake #1: Task/tech lists instead of outcomes
Why does it read “IC”? It proves you shipped work, but not that you owned impact or direction. Hiring managers can’t tell what changed because of you.
Fix: Rewrite bullets as Outcome → Scope → Decision → Proof (keep the tech as supporting detail, not the headline).
Example rewrite:
Instead of: “Migrated services to Kubernetes using Helm and ArgoCD.”
Try: “Improved release reliability and cut deployment time 45→8 minutes across 12 services by standardizing delivery (ArgoCD/Helm) and aligning teams on one release workflow.”
Mistake #2: “Led X engineers” with no leadership mechanics
Why does it read “IC”? Headcount is a fact, not evidence. Without how you lead, it looks like people management without ownership.
Fix: Add your operating cadence + constraints + cross-functional surface area (how you set direction and keep delivery moving).
Example rewrite:
Instead of: “Led a team of 6 engineers.”
Try: “Led 6 engineers across 2 squads; set quarterly priorities with Product, ran weekly execution reviews, and unblocked delivery by renegotiating scope/dependencies.”
Mistake #3: Stakeholders are invisible (influence stops at your code)
Why does it read “IC”? Leadership is influence under ambiguity. If Product/Security/Legal/Finance never appear, it looks like you only led yourself.
Fix: Name stakeholders + tradeoffs + alignment artifacts (how you earned buy-in: RFCs, roadmap alignment, risk reviews, decision logs).
Example rewrite:
Instead of: “Implemented SSO improvements.”
Try: “Aligned Security, Legal, and Platform on an identity roadmap; introduced risk-based rollout gates and secured buy-in for a phased migration with minimal customer disruption.”
Why does it read “IC”? Without measurable impact, your work feels like an activity. Vanity metrics (“improved performance”) don’t translate into business value.
Fix: Pick one metric that maps to business outcomes: reliability, speed, revenue protection, cost, risk reduction.
Example rewrite:
Instead of: “Improved system performance.”
Try: “Reduced p95 latency 420ms→180ms, improving checkout completion and lowering infra cost by ~18% through query optimization and caching changes.”
Mistake #5: Ownership boundaries unclear (what was actually yours?)
Why does it read “IC”? If it’s unclear what you owned end-to-end, it reads like a contribution on someone else’s plan.
Fix: Show the zone you owned: a roadmap slice, platform/domain, KPI, or a program with clear boundaries and outcomes.
Example rewrite:
Instead of: “Worked on observability and incident response.”
Try: “Owned reliability for Payments (SLOs + incident process); reduced Sev-1 incidents by 35% by introducing error budgets, standardized runbooks, and on-call load balancing.”
Mistake #6: Over-indexing on tools and under-selling decisions
Why does it read “IC”? Tools are replaceable; decisions are leadership. If your bullets are mostly “used X,” you’re signaling implementation, not judgment.
Fix: Add one sentence on the tradeoff and why it mattered (what you chose, what you avoided, and the reason).
Example rewrite:
Instead of: “Implemented Kafka for event streaming.”
Try: “Chose Kafka over synchronous APIs to decouple teams and reduce failure propagation; introduced schema governance to prevent breaking changes as the org scaled.”
Mistake #7: Generic summaries (buzzwords) instead of a leadership thesis
Why does it read “IC”? “Results-driven, collaborative, passionate about innovation” tells nothing. Leaders have a clear point of view on what they build and how they lead.
Fix: Write a one-line positioning statement: “I build ___ by leading ___ to achieve ___.”
Example rewrite:
Instead of: “Engineering leader with strong communication skills.”
Try: “I build reliable platforms by leading cross-functional teams to improve delivery speed and reduce operational risk at scale.”
10-minute Teardown Checklist
Open your CV/LinkedIn and scan it like a hiring manager would— extremely fast. In 10 minutes, you can spot (and fix) the most common “great engineer, not ready to lead” signals.
Check your top section (headline + most recent role) and answer:
Do your top 3 bullets contain a number? If not, add one outcome metric (speed, reliability, cost, revenue protection, risk reduction). Even a directional metric beats none.
Do you name stakeholders? Look for at least one mention of who you aligned with (Product, Security, Legal, Finance, Sales, other teams). Leadership shows up as influence.
Do you show one tradeoff? Add a single sentence that proves judgment: what you chose, what you didn’t, and why (build vs buy, risk vs speed, scalability vs time-to-market).
Do you state the scope? Make the size of the problem obvious: domain/platform owned, #services/squads, users/regions, budget, or a KPI you owned end-to-end.
If you can’t answer “yes” to at least 3 out of 4, your profile is probably underselling your leadership readiness, regardless of how strong your actual work is.
Key Takeaways
Leadership readiness is a signal game. Your CV/LinkedIn needs to show scope, judgment, influence, and outcomes right from the beginning.
Tools don’t get you promoted—decisions do. Keep tech as a supporting detail, but lead with the tradeoffs you made and why they mattered.
Ownership must be obvious. Make it clear what you owned end-to-end (domain/platform/KPI), who you aligned with, and what changed as a result.
One strong metric beats five vague claims. Pick a single business-relevant measure (speed, reliability, cost, revenue protection, risk reduction) and anchor your top bullets to it.
Bottom line: If your profile reads like a changelog, it will be evaluated like an IC profile—even if you’re already leading.
Stop guessing what ‘senior-ready’ means. Score yourself across 9 executive competencies, then turn gaps into a 30–60 day plan.
Here’s the simplest way to think about an engineering manager promotion: your title changes when senior leaders can trust you with outcomes they’re accountable for. Not effort. Not hours. Just four outcomes: revenue, cost, risk, and speed.
This promotion readiness checklist is designed to help you measure that trust quickly, honestly, and in a way you can act on. It’s also mapped to a structured development path, built to develop commercial fluency, strategic vision, and executive readiness.
See the 9-module roadmap
Practitioner-led roadmap built for working tech leaders with lifetime access and 10,000-strong community of tech leaders to peer-proof your decisions.
Promotions aren’t granted for effort—they’re granted when leaders can trust you with business outcomes (revenue, cost, risk, speed).
Use the scorecard table to rate yourself 0/1/2 across 9 senior-leadership competencies. Score evidence, not intent.
Your fastest path to an engineering manager promotion is to close your lowest 2 gaps—not to “do more.”
Right after you score yourself, take the Skills Assessment test to benchmark your strengths and weaknesses against other tech leaders and confirm what to focus on first:
Then run a simple 30–60 day plan for each gap:
Produce one executive artifact (strategy memo, KPI tree, risk register, investment case)
Have one stakeholder alignment conversation
Deliver one measurable outcome
Table of Contents
Get the IT Career Path Roadmap (Free PDF)
Want more than scattered ideas? Get our IT Career Path Roadmap PDF – an 8-step framework to map your next roles, sharpen your skills, and build a layoff-resilient tech leadership career. Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
Why Strong Engineering Managers Still Get “Not Yet”
If you’re in an engineering manager career stage where you’re already delivering reliably—shipping, stabilizing, mentoring—and you still hear some version of:
“You’re doing great! Keep going.”
“We need to see you operate at a bigger scope.”
“You’re not quite ready…yet.”
…it usually isn’t because you’re missing grit. It’s because your work is still being evaluated as execution, not executive leverage.
At senior levels, the question changes from:
“Can you get things done?” to
“Can you set direction, scale outcomes through others, and make trade-offs that protect the business?”
If your impact isn’t visible in business terms—or it only exists inside the engineering org—you’re at risk of becoming the “high-performing ceiling.” The person everyone relies on, but no one promotes, because promoting you would remove the safety net.
That’s the uncomfortable truth. And it’s why a scorecard like this works: it forces the conversation away from vibes and toward evidence.
How Promotions Actually Happen at Senior Levels
Senior promotions are trust transfers
When you step into Director/VP territory, leadership is transferring a real bundle of risk to you:
You start showing judgment with incomplete information.
Proof beats potential
Senior leaders don’t promote “potential.” They promote repeatable evidence of operational excellence that converges technology and business outcomes.
If you want a real-world reference point, compare your current behaviors to a public engineering manager competency framework; for example, GitLab’s Engineering Manager job family, which spells out what ‘good’ looks like in team health, delivery ownership, and leadership systems.
This checklist is designed to a) generate that evidence, and b) make gaps painfully obvious in a useful way.
How to Use This Promotion Readiness Checklist (~8 minutes)
Score each competency 0 / 1 / 2:
0 = not demonstrated (or only in narrow, low-stakes contexts)
1 = emerging, inconsistent, needs support
2 = demonstrated repeatedly, visible to stakeholders, produces outcomes
Then add your total.
Interpretation:
0–6: foundation gaps (you need deliberate reps + feedback loops)
7–12: promotable with targeted gap-closing
13–18: operating at senior level (your next move is narrative + influence surface area)
One rule: score evidence, not intent. If your VP couldn’t confidently repeat it in a promo discussion, it’s not a “2.”
Engineering Manager Promotion Readiness Checklist: The 9-signal Scorecard (table)
Note please that the nine competencies below should align to the nine executive-level modules in a technology leadership program (so your gap-closing plan can map directly to a structured curriculum).
Competency (Signal)
What senior leaders look for (Executive signal)
Proof points (Score = 2)
Common traps (why you stall)
Fast move (7–14 days)
Module mapping (Digital MBA)
Leadership & Team Building
You scale outcomes through people and systems
Predictability improves without heroics; retention improves; you build successors
You become the bottleneck; “being helpful” replaces “building performance”
Run a friction audit → top 3 blockers + one fix each; set a lightweight operating cadence
Leadership & Team Building
Business Fundamentals
You understand the business model and speak in business terms
You can link your work to margin/growth/churn; you’ve reframed initiatives into business cases
“Business is politics”; measuring only internal metrics
Build a 1-page business model map; ask Product/Finance for top 3 constraints this quarter
Business Fundamentals
Technology Strategy & Business Goals
You set direction, not just execute
You can present a 6–12 month strategy; you’ve made hard trade-offs with stakeholder alignment
Strategy = architecture preference; alignment too late
Write a 1–2 page strategy memo: goals, constraints, 3 bets, success metrics; socialize it
Tech Strategy & Business Goals
Personal Development (Presence & Influence)
You’re trusted in high-stakes rooms
You drive meetings to decisions; your writing gets forwarded; you handle conflict cleanly
Waiting to be noticed; confusing visibility with self-promotion
Send a weekly exec update: outcomes/risks/asks/next; rewrite as “what changed”
Personal Development
Product Development
You deliver value, not output
Roadmap ties to customer outcomes; cycle time improves; strong product partnership
Treating product as requirements; shipping without metrics
For one initiative: define problem → success metric → rollout → learning loop
Product Development
Information Management (Risk/Security/Resilience)
You own risk like an executive
You quantify risk; postmortems change systems; resilience improves over time
“Security is someone else’s job”; only reacting after incidents
Create a top-5 risk register (likelihood/impact/mitigation/owner); review with a stakeholder
Information Management
Finance & Funding
You justify investments and manage budgets
You can forecast costs; explain variance; compare options (build vs buy/capex vs opex)
Finance = bureaucracy; no unit economics literacy
Write a 1-page cost story (drivers, levers, risks); review with Finance
Finance & Funding
Data Science & Analytics
You make decisions with evidence
You use leading indicators; instrumentation improves; prioritization is metrics-driven
Vanity metrics; measuring what’s easy
Build a KPI tree: business outcome → levers → operational metrics
Data Science & Analytics
Digital Trends & Innovation
Build a 1-page business model map; ask Product/Finance for the top 3 constraints this quarter
Experiments with success criteria; you can say “no” credibly; balance innovation with risk
Shiny object syndrome; innovation theater
Create an innovation intake template: problem, hypothesis, cost, risk, decision date
Digital Trends & Innovation
Explore the Structured Path
If you want to close your lowest scores with a structured path, the Digital MBA includes 9 executive-level modules, 200+ practitioner-led micro-lectures, weekly Q&As, and peer learning—designed to fit around full-time work.
What Does Your Score Really Mean (and what to do next)
If you scored 0–6: you’re not behind; you’re under-instrumented
This is the stage where your engineering manager career can feel confusing: you’re working hard, you’re respected, but you don’t have a system for growing into a senior scope.
Your job isn’t to “do more.” It is to start producing executive evidence.
Start with two moves:
Pick one competency to raise from 0 → 1 this month.
Pick one artifact that makes your progress visible (more on artifacts below).
If you scored 7–12: you’re closer than you think
This is the sweet spot: you’re already promotable in some dimensions, but you’re inconsistent in others. Promotions often stall here because leaders can’t predict your performance at a higher scope.
Your job is to close the two lowest gaps and make the improvement obvious.
If you scored 13–18: you’re operating at a senior level; tighten the narrative, widen the surface area
At this level, your technical leadership is likely strong. Your risk is different: you may be doing senior work, but in a way that isn’t being seen by the people who decide titles.
Your job now is to:
Widen the influence (cross-functional ownership)
Tighten the narrative (make your outcomes repeatable)
Increase the decision-making exposure (be in the rooms where trade-offs happen)
Want a benchmark, not just a self-score?
If you’ve scored yourself honestly, here’s the next step: take CTO Academy’s Technical and Management Leadership Skills Assessment to benchmark your strengths and weaknesses against hundreds of global tech leaders who’ve already completed the process.
Conversation: review with Security/Platform/Compliance stakeholder
Outcome: mitigation started on 1 high-impact risk (and tracked)
This is what senior leadership is looking for: not “busy,” but directional judgment plus repeatable evidence.
Build Your Executive Proof Portfolio
Here, we are referring to the artifacts that drive the promotion conversation. You see, promotion discussions are not won with intent. They’re won with artifacts that get repeated.
Therefore, if you want to accelerate your promotion path, build a portfolio that showcases your executive thinking.
(click to enlarge/download)
1) The strategy memo (1–2 pages)
What does it do? It proves you can set direction and align stakeholders.
Include:
Goals (business outcomes, not internal initiatives)
Current constraints (what’s true right now)
3 bets (and what you’re not doing)
Success metrics (what changes if you’re right)
2) The KPI tree (one page)
What does it do? It proves you can translate engineering into business outcomes.
Start with the business outcome, then break it down:
Business Outcome → Leading Indicators → Operational levers → Engineering Metrics
When you’re choosing delivery signals, anchor your dashboard in evidence-based measures like DORA’s four key metrics—a simple way to balance speed and stability without falling into vanity metrics.
3) The risk register (top 5)
What does it do? It proves executive-level ownership.
What does it do? It builds visibility without self-promotion.
Format:
Outcomes (what changed)
Risks (what could break)
Asks (decisions or support needed)
Next (what happens next week)
This portfolio is what turns “great engineering manager” into “obvious next-level leader.”
How to Think About Your Broader Engineering Manager Career (so you don’t optimize the wrong thing)
A promotion scorecard works best when it fits inside an actual career map. Otherwise, you end up maxing out one role and missing the bigger trajectory. In other words, you might unwittingly optimize the wrong thing.
If you want a bigger-picture framework…
If you want a bigger-picture framework for your engineering manager career, you can use CTO Academy’s Tech Career Master Guide to map milestones and stay resilient—especially in an AI-shaped market.
The career guide helps you choose where you’re going
This scorecard helps you decide what to build next
Your proof portfolio makes the change visible to the people who decide promotions
A Structured Path to Close Your Gaps (without pausing your job)
If your scorecard reveals predictable gaps—strategy, finance, influence, risk—here’s the honest question:
Do you want to patch those gaps by collecting random content, or do you want a structured, practitioner-led path that’s designed for technology leaders?
CTO Academy’s Digital MBA for Technology Leaders is explicitly positioned around the shift you’re trying to make: commercial fluency, strategic vision, and executive readiness—without stepping away from work.
What makes it fit an engineering manager promotion timeline
9 executive-level modules mapped to the exact competencies above
200+ practitioner-led micro-lectures with supporting resources, tests, and flashcards
Weekly Q&A sessions and peer learning (so you’re not learning in isolation)
A delivery model built for busy schedules (released in modules, with a consistent structure)
Lifetime access and up to 12 months to complete
No capstone project (designed to integrate with working life)
A CPD-certified completion certificate
Your Next Step
If you’re ready to close your gaps with a structured path, explore the Digital MBA for Technology Leaders and join the next cohort (date shown on the program page).
What is an engineering manager promotion readiness checklist
An engineering manager promotion readiness checklist is a structured way to assess whether you’re demonstrating the competencies senior leaders associate with higher scope. These are: strategy, business alignment, risk ownership, financial framing, and the ability to scale outcomes through teams. The goal isn’t to “score high.” It is to identify gaps and produce visible proof points that de-risk your promotion.
How do I know if I’m ready for an engineering manager promotion?
You’re likely ready when you can show repeatable evidence in at least a few of these areas: – You set direction (not just deliver) – You translate engineering into business outcomes – You make and defend trade-offs – You manage risk proactively – You scale outcomes through people and systems If those show up consistently—and stakeholders beyond engineering can see them—you’re closer than you think.
What proof points matter most for senior engineering manager promotion decisions?
The most persuasive proof points are forwardable artifacts plus measurable outcomes. Examples: – A strategy memo that aligns stakeholders – KPI tree tied to business outcomes – Risk register that drives mitigations – Investment case that speeds decisions – Weekly exec updates that show judgment and clarity In promotion conversations, these artifacts help others tell your story for you.
How long does it take to become promotion-ready?
If you’re already operating as a strong engineering manager, targeted gap-closing often takes 30–60 days to produce meaningful proof points, assuming, of course, you pick the right gaps and create visible artifacts. Longer-term readiness (especially for Director scope) comes from repeating those behaviors until they’re consistent and trusted.
Key Takeaway
You don’t get promoted because you want it. You get promoted when leadership can confidently say: “They’ve already been doing the job—at a higher scope—and the business is safer with them owning it.” Hence, the keywords of the modern tech leadership career: owning it.
Use the scorecard. Build the proof portfolio. And if you want a structured path that maps to the same executive competencies—strategy, finance, influence, risk, and leadership systems—the Digital MBA for Technology Leaders is built for exactly that transition.
Here’s the uncomfortable truth about your IT career path up front: the old way of “working hard, getting promoted every few years, and eventually landing a senior title” no longer works in tech.
Over the last few years — and especially in 2025 — we’ve watched wave after wave of layoffs, hiring freezes, and quiet org reshuffles. Whole teams disappear after a re-org. Middle management layers get squeezed. Gen AI turns from a curiosity into a serious force in how software is built and how many people you “need” to create it. At the same time, there are still plenty of roles out there… just not for everyone or every profile.
So the real question isn’t “Is there still an IT career path?”
It’s “How do I design my IT career path that actually survives this?”
This guide is written for precisely that purpose. Not to give you yet another list of job titles and salaries, but to help you map a path that stays relevant and valuable as the market keeps shifting. It covers the way from individual contributor to senior leadership.
We’ll look at how layoffs, Gen AI, and the “Great Flattening” are changing the shape of careers, and then we’ll build a practical roadmap around three pillars:
Business-visible impact, making sure your work shows up in revenue, cost, risk, or speed.
Scarce, evolving skills, especially around systems, data, security, teams, stakeholders, and AI.
Role mobility & networks, so you can move up, sideways, or across companies when you need to.
If you’re serious about reaching senior leadership — and staying employable on the way there — this is your starting point.
Download the PDF version of this guide
Want to work through this roadmap properly – not just skim it in a tab? Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
TL;DR
The old “work hard, get promoted every few years” pattern is broken. Layoffs, Gen AI, and flatter orgs mean neither junior ICs nor average managers are safe by default.
The careers that survive and progress are built on three pillars:
Pick a primary lane (IC or leadership), then map 2–3 roles ahead and deliberately build the skills and proof you need at each step.
Aim for one business-visible outcome per year and document it properly – this becomes your “anti-layoff” portfolio for promotions, reviews, and job searches.
Use AI as a force multiplier, not a threat: automate toil, improve quality, and show measurable gains for your team, especially as you move into senior IC and leadership roles.
Design mobility through smart rotations (product, infra, data, security) so you’re not locked into a single narrow niche or company type.
Build a small bench of sponsors, not just mentors – people with influence who know your work and will put your name on the list when roles and projects are being discussed.
If you’re 2–7 years in and want to lead your first team (or become a real tech lead, not just “senior who organises stand-up”), the Future Leaders Courseis the best next step.
If you’re already leading teams or managers and need to think and operate like a VP/CTO in the AI era, the Digital MBA for Technology Leaders is where you build that executive toolkit.
Table of Contents
The New Reality for IT Career Paths (Layoffs, GenAI, Flattening)
If your career has felt a bit, well, unstable lately, it’s not your imagination.
Over the last couple of years, the numbers have swung hard:
Senior leaders talk about “fewer layers,” “more direct ownership,” and “no more managers managing managers.”
New job postings for traditional mid-level manager roles have dropped sharply in many markets.
So if you’re:
A junior or mid-level IC: you’re competing in a tighter market with fewer entry points.
A tech lead or engineering manager: you’re in the band that is most exposed when companies decide the org chart is “too thick in the middle.”
What this actually means for you
The uncomfortable bit: neither junior ICs nor “average managers” are safe by default anymore.
The good news: there is a pattern in who tends to keep their seat, land on their feet quickly, or even get promoted during all this.
Layoff-resilience tends to flow to people who:
Move the P&L (Profit & Loss) You can show how your work affects revenue, margin, cost, risk, and speed, and others in the business would back that up.
Run critical systems or platforms You’re not just building features; you’re responsible for infrastructure, platforms, data, or security that the rest of the organization depends on.
Lead AI-augmented teams and bigger spans You know how to plug GenAI and automation into workflows safely, and you can manage more people or more scope with them, not fewer.
That’s the new bar.
So the real challenge becomes:
How do you design an IT career path that is not only successful on paper, but stays resilient under these conditions?
That’s what we’ll tackle next, starting with the three pillars your career needs to stand on.
The Three Pillars of a Layoff-Resilient IT Career
Job titles come and go. Tech stacks change. Even entire layers of management can vanish after a re-org.
What actually keeps you employed and progressing isn’t your title or the logo on your LinkedIn profile, but the shape of the value you create.
In this new environment, that value rests on three pillars.
1. Business-visible impact
Being “smart” or “busy” is no longer enough. The people who keep their seat – and get the interesting opportunities – are the ones whose work shows up in the numbers.
That means you can point to things like:
Revenue: “We increased trial-to-paid conversion by 8%.”
Cost: “We cut cloud spend by 15% without hurting performance.”
Risk: “We reduced critical incidents by 40% and tightened our security posture.”
Speed: “We brought release cycle time down from monthly to weekly.”
As you move toward senior leadership, this shifts from “my feature shipped” to “my decisions materially moved a KPI the business cares about.”
2. Scarce, evolving skills
The second pillar is what you know and can do, especially in areas that are harder to automate and harder to hire for.
Think along three lines:
Systems & platforms – architecture, reliability, observability, internal platforms.
Security & data – governance, privacy, compliance, data quality.
Gen AI & automation – not just “I use a coding assistant,” but “I can safely weave AI into products and internal workflows.”
Tools will change. What matters is that you keep moving towards higher-leverage, harder-to-replace skills.
3. Role mobility & networks
Finally, resilience comes from your optionality.
Can you move:
From a feature team to a platform or security team?
From startup to enterprise, or into a different sector altogether?
From IC to tech lead, or back again if the organization flattens?
That kind of mobility is powered by relationships (mentors, sponsors, peers) and a portfolio of work people can vouch for.
(click to enlarge/download)
8 Steps to a Layoff-Resilient IT Career
Rather than giving you a random list of tips, this guide is structured as a sequence of 8 steps you can actually work through.
Here’s the roadmap at a glance:
Understand the new reality Get clear on how layoffs, Gen AI, and flatter orgs are changing the rules for IT careers.
Choose your primary lane Decide whether you’re optimising for the IC track or the leadership track (for now), so you can stop drifting and start aiming.
Build a layoff-resilient skill stack Map 2–3 roles ahead and design the mix of technical, business, and AI skills you’ll need to get there.
Make your impact visible Create an “anti-layoff” portfolio by driving at least one clear, business-visible outcome each year and telling that story well.
Design role mobility Use rotations and domain switches (product, infra, data, security, different org types) to keep your career portable.
Build your sponsor bench and network Move beyond “I know some people” to having sponsors who will put your name on the list when roles and projects are decided.
Turn AI into an advantage at your level Use AI differently as a junior, senior IC, manager, or exec – always to raise your leverage, not replace yourself.
Select your next step and support path Translate all of this into concrete actions: the next two roles you’re aiming for, the pillar you’ll strengthen first, and whether you’re ready for structured help via Future Leaders Course or the Digital MBA for Technology Leaders.
The rest of the article walks through each of these steps in detail, so you can turn “I hope my career survives this” into “I know what I’m building and why.”
Now, let’s turn the three pillars into a concrete career map, so you’re not just hoping your role survives the next change; you’re deliberately building a profile that companies fight to keep.
Step 1: Choose Your Lane and Destination (IC vs Leadership, in an AI World)
Before you can map a career path, you need to decide which lane you’re primarily driving in.
You don’t have to lock yourself in forever. People switch lanes. But being fuzzy here is one of the quickest ways to drift from promotion cycle to promotion cycle without a clear direction.
Two Main Ladders: IC and Leadership
Most tech organisations now recognise two parallel ladders.
The IC ladder
This is the path where you stay “hands-on” for most of your career, but your scope gets much bigger:
Mid Engineer → Senior Engineer
Staff Engineer → Principal Engineer → Distinguished/Architect
At the top of this ladder, you’re not just shipping tickets. You’re:
Owning systems and platforms that other teams depend on
Shaping architecture and technical strategy
Influencing decisions across product, security, data, and operations
It’s a highly resilient path when you:
Deliver business-visible impact (pillar 1) through your systems
Invest in scarce skills like reliability, security, data, and AI integration (pillar 2)
Maintain mobility across teams, domains, and industries (pillar 3)
The Leadership ladder
This is the path where you’re ultimately responsible for people, delivery, and outcomes:
Tech Lead/Team Lead
Engineering Manager
Head of Engineering/Director
VP Engineering/CTO/CIO
Here, your day-to-day work is less about writing code and more about:
Can move between types of organizations and structures (pillar 3)
Both ladders can take you to senior levels. The question is which kind of work energizes you more and where you can most naturally build those three pillars.
How Layoffs + Gen AI Change the Choice
If you’d asked this question ten years ago, the advice would have been more straightforward: “Pick what you enjoy.”
You still need that, but the environment has changed.
On the IC lane
GenAI is steadily eating away at routine coding work:
Boilerplate
Simple integrations
Tests and documentation
That doesn’t make ICs obsolete. It just moves the value:
Up into architecture and system design
Sideways into integration, reliability, observability, and governance
Outwards into data, security, and AI-enabled products
If you’re staying on the IC track, the safe ground is to become the person who:
Designs the systems others build on
Keeps critical platforms healthy, secure, and cost-effective
Knows how to use AI tools safely and effectively, and can help others do the same
On the Leadership lane
Flattening has made it very clear what’s not needed: low-impact, middle-layer managers who mostly shuffle work around.
The leaders who remain are expected to:
Manage bigger spans of control.
Run clear operating systems (cadence, metrics, decision-making).
Use AI and automation to make their teams faster and more effective, not just “busy.”
So if you’re on the leadership track, your resilience comes from being able to:
Show that your group is moving key business metrics.
Handle complexity across multiple teams and stakeholders.
Steer how AI and automation are adopted in your area, rather than being surprised by them.
So the lane choice isn’t “hands-on vs people person” anymore. It’s:
“Where can I build the strongest combination of impact, scarce skills, and mobility in an AI-shaped, flatter organization?”
Quick Self-Test: Which Lane Are You Leaning Toward?
There’s no correct answer here, but there are strong hints. Answer these with a simple yes/no, and notice which side gets more “yes.”
You might be leaning toward the IC lane if:
I get genuine energy from deep technical problems, debugging, and system design.
I’d rather spend most days creating or improving systems than being in back-to-back people meetings.
I enjoy mentoring, but I don’t feel a strong pull to be responsible for someone’s performance review and career.
I like the idea of being the “go-to person” for a critical platform, domain, or technical decision.
You might be leaning toward the Leadership lane if:
I get energy from helping other people perform better, not just from doing the work myself.
I naturally think about the bigger picture; i.e., business goals, trade-offs, customers, costs.
I’m comfortable making decisions with incomplete information and taking responsibility when things go wrong.
I’m curious about budgets, headcount, hiring, and team organization.
I’m already informally coordinating people or projects, even without the title.
If you found yourself nodding along with both sets, that’s normal. Early in your career, many people sit in the overlap. The goal isn’t to make a perfect, irreversible decision; it’s to choose a primary direction for the next few years so you can build momentum instead of drifting.
And if you’re leaning toward leadership but haven’t officially led a team yet, this is the moment to get deliberate.
Remember, the step from senior IC to first-time manager is where many careers stall or derail.
That’s exactly the gap the Future Leaders Course is designed to fill – helping you learn how to run people and delivery like a business, not just write more code under a new title.
Step 2: Build a Layoff-Resilient Skill Stack (Technical, Business, AI)
Once you’ve picked a lane, the next question is: what are you actually building toward?
“Be better at my job” is not a plan. “Become a Staff Engineer” or “run an engineering org” is. This is where you get specific about 2–3 roles ahead and the skills you’ll need to be the obvious candidate when those opportunities appear.
Map 2–3 Roles Ahead for Your Chosen Lane
Start with where you are today and write down the next two or three roles you can realistically grow into in your lane.
Then, for each step, capture:
The core skills you’ll need
The proof you can show (projects, metrics, responsibilities)
A simple way to structure it:
Current role
Target role(s) (2–3 steps ahead)
Key skills to build
Proof you’ll need
Mid/Senior Engineer
Staff Engineer → Principal Engineer
System design, platform ownership, reliability, AI-assisted dev, mentoring
Successfully led a team or project end-to-end; demonstrated measurable impact (cost, speed, revenue); handled performance and feedback well
Senior Engineer/Tech Lead
Engineering Manager → Head of Engineering
People leadership, delivery management, stakeholder comms, basic finance, AI-in-team workflows
Org design, portfolio thinking, budgeting, influencing up, and AI strategy
Org design, portfolio thinking, budgeting, influencing up, AI strategy
Manage multiple teams; own a budget; run a multi-team initiative; show how your area contributed to company goals
You don’t need a perfect plan. You need enough clarity that you can ask:
“Given the role I want in 12–36 months, what am I missing and how do I start closing that gap now?”
Technical & Gen AI Skills That Age Well
Technology stacks come and go. Some skills, however, keep paying off because they sit closer to the core of how systems and organizations work.
On the technical side, aim to grow into work that touches:
Systems & platforms
Architecture and design
Internal platforms and shared services
Observability, monitoring, and performance
Security & data
Access control, privacy, compliance basics
Data modelling and data quality
Understanding how data flows through the business
Reliability
Incident response and post-mortems
Capacity planning
Designing for failure and graceful degradation
On the AI side, you want more than “I use ChatGPT sometimes”:
AI-assisted development and testing
Using tools to scaffold code, generate tests, and refactor safely
Combining AI output with sound engineering judgement
Understanding limitations, evaluation, and risk
Knowing where not to use GenAI (security, privacy, regulatory constraints)
Basic prompt design and evaluation
Awareness of bias, hallucinations, and failure modes
At the junior level, the goal is to get out of pure “ticket taker” mode as fast as you can:
Don’t just close Jira tickets.
Volunteer to own a small service, feature area, or internal tool end-to-end.
Learn how that piece fits into the wider system and what metrics it affects.
At mid to senior level, look for chances to:
Take responsibility for a platform or critical subsystem.
Lead improvements that increase engineers’ productivity (CI pipelines, test automation, dev tooling, AI integrations).
Those are the kinds of skills and responsibilities that make you harder to replace and easier to promote.
Business Skills for Every Technologist
Whether you stay on the IC side or go deep into leadership, business literacy is now part of the job.
At a minimum, you should be comfortable with:
Impact metrics
Understanding the KPIs your team affects (revenue, costs, risk, time-to-market).
Being able to explain your work in those terms.
Basic finance
The difference between OPEX and CAPEX.
What “margin,” “runway,” “payback period,” and “ROI” actually mean in your context.
Stakeholder management
Communicating clearly with non-technical counterparts.
Managing expectations, trade-offs, and scope without drama.
Prioritization
Choosing between good options based on business value, not just technical elegance.
Saying “no” or “not now” with a clear rationale.
If you’re on (or moving toward) the leadership track, add another layer:
Portfolio thinking
Seeing your teams and projects as a portfolio of bets with different risk/return profiles.
Deciding where to invest more, where to cut, and where to experiment.
Budgeting and resource planning
Understanding how headcount, tools, and infrastructure translate into costs.
Being able to argue for (or against) spending with numbers.
Roadmap economics
Evaluating the business impact of roadmap items.
Sequencing work to deliver value early and often, not just “big bang” launches.
These skills are what turn “good at tech” into “trusted to lead and allocate resources,” and they matter just as much in a Staff Engineer role as they do in a Head of Engineering role.
Bridge the gap between tech and leadership.
Designed exclusively for ambitious technology leaders, the Digital MBA equips you with the tools, mentors, and network to scale your impact and transform from an experienced technologist into a confident, strategic leader.
If you’re reading this and thinking, “I’m comfortable technically, but I’m guessing on the business side,” that’s a signal. The sooner you close that gap, the more options you’ll have.
And if you’re leaning toward leadership but haven’t yet had structured support on things like influence, communication, and the business basics, that’s precisely where the Future Leaders Course comes in. It helps you move from “senior engineer who sometimes leads” to someone who can talk credibly with the business and run a team without losing yourself in the process.
Step 3: Make Your Impact Visible (Your “Anti-Layoff” Portfolio)
At this point, you’re building the right skills. But skills on their own don’t keep you safe.
What really matters when companies are deciding who to keep, who to promote, and who to let go is simple:
Can anyone clearly see the value you create?
That’s what your “anti-layoff” portfolio is for.
One Business-visible Outcome per Year
A practical rule of thumb: aim for one clearly business-visible outcome every year.
Not “I worked really hard,” but something you can describe in terms of:
Reduced cost – infra spend, tooling, support overhead
Faster delivery – cycle time, lead time, time-to-market
A few simple examples:
Reduced cost “We redesigned our data pipeline and storage strategy. Cloud spend on that workload dropped by 18%, while query latency improved by 25%.”
Increased revenue “I led the implementation of a new onboarding flow. Trial-to-paid conversion went from 21% to 27% over three months, adding roughly $X/month in recurring revenue.”
Reduced risk “We introduced a new incident response playbook and alerting. Critical incidents went from 10 per quarter to 4, and average time to recovery dropped by 40%.”
Faster delivery “I drove the rollout of trunk-based development and better CI. Our median lead time from merge to production went from 3 days to under 1 day.”
You don’t need a miracle every year. But you do need one thing you can point to and say:
“That wouldn’t have happened the same way without me, and here’s how we measured it.”
Storytelling: How You Document and Communicate Impact
Collecting these wins isn’t enough. You also need to tell the story well.
A light-weight structure that works:
Situation: What was going wrong or holding us back?
Task: What were we trying to achieve?
Action: What did you do?
Result: What changed, in numbers and in outcomes?
You don’t have to write a novel. Two or three tight sentences per story are enough:
“Our release cycle was stuck at monthly, and stakeholders were constantly frustrated. I proposed and led a shift to trunk-based development with better automated testing (Action). Within four months, we were shipping weekly (Result), and incidents per release dropped by 30% (Result).”
And this is where this kind of narrative really matters:
Performance reviews Don’t rely on your manager to remember everything. Bring your own impact doc.
Promotion packets Promotion panels want to see patterns: scope, outcomes, consistency. Your stories are the raw material.
Job searches (especially after layoffs) When you’re competing against dozens of other CVs, “I was responsible for X” is weak. “Here’s what I changed and how we measured it” is strong.
Make it a habit:
Keep a simple “brag document” or impact log.
Update it monthly with bullet points and rough numbers.
When review or promotion time comes, you’re not staring at a blank page.
AI as Leverage, Not Threat
Gen AI and automation show up in layoff narratives, which makes them feel scary. But from a career perspective, they’re also a great way to quickly build proof of impact.
Think in terms of AI as a multiplier, not a competitor.
Concrete examples:
Testing
You introduce AI-assisted test generation for a legacy service.
Regression test coverage doubles in a quarter, and regression-related incidents drop by 30%.
Your story: “I used GenAI to expand test coverage and reduce escaped bugs.”
Documentation
You use AI to generate and clean up internal docs, API references, or runbooks.
New joiners ramp up faster; onboarding time for engineers drops from 6 weeks to 4.
Your story: “I systematized our documentation using AI tools, cutting onboarding time by a third.”
Internal tooling & workflows
You build a small internal tool with an AI component (e.g., a log summarizer, a query assistant, or a support-response helper).
Support or on-call workload drops, or time-to-diagnose issues improves significantly.
Your story: “I built an AI-backed internal tool that reduced average investigation time from 2 hours to 45 minutes.”
The key is that you are the one:
Spotting where AI can safely help
Designing how it fits into the workflow
Measuring what changed
That’s the difference between “someone told us to use AI” and “I led an AI-driven improvement that made us measurably better.”
Over a few years, an anti-layoff portfolio might look like:
2025 – “Led a cross-team project that improved conversion by 6%.”
Those stories, repeated and refined, do a lot of quiet work for you when the organization is deciding who’s essential, and, maybe even more importantly, when you’re ready to move to your next role.
Step 4: Design Role Mobility (Rotations, Domain Switches, Org Types)
Even if you love your current role, it’s risky to build a career that only works in one particular niche.
Layoffs and re-orgs don’t ask whether you’re happy. They ask whether your skills and experience are portable.
That’s where role mobility comes in. It is the ability to move up, sideways, or across when you need to.
How Does Mobility Protect You in Downturns
Mobility gives you options when your current role on the org chart no longer exists.
If your only story is “I’ve done this one thing in this one type of company,” you’re much more exposed than someone who can credibly say:
“I’ve worked in both product companies and internal IT.”
“I’ve moved between infra/platform and product teams, and I understand both.”
“I’ve delivered in different industries – say, fintech, health, SaaS – and I know how to adapt.”
A few examples of how this plays out:
Your B2C SaaS startup gets acquired, and the product is retired. If you’ve only ever worked on consumer apps, moving into an internal platform team or a B2B product is much easier when you’ve already done one rotation that looks like that.
Your internal IT department outsources a chunk of work. If you’ve already spent time on customer-facing product teams or in a different sector, you can pitch yourself for roles that rely on your domain understanding, not just your current job title.
A heavily regulated industry tightens budgets. If you’ve had a rotation in less regulated, faster-moving environments, you can point to examples of times when you adapted and still delivered safely.
Mobility is not random job-hopping. It’s deliberate exposure to different types of work, so you’re not tied to one narrow pattern of “I only know how to do X in Y context.”
High-Leverage Rotations by Level
You don’t need a dozen rotations. One or two well-chosen moves can change your career trajectory.
Here are some high-leverage options:
At the junior level
You want to break out of the generic “developer #47 on feature team #6” territory and into roles that give you more system understanding.
Good moves include:
Support → backend → platform
Start in support or customer engineering, then move into backend, and finally into internal platforms or tooling.
You learn how users actually struggle, then how systems behave, then how to make developers more productive.
Infra → SRE
If you’re in infra or ops, rotating into Site Reliability Engineering gives you exposure to reliability, automation, and cross-team collaboration.
These skills travel well across companies and industries.
Data-adjacent rotations
Spend time working closely with data pipelines, analytics, or BI.
Understanding how data is produced, cleaned, and used in decisions makes you more valuable almost everywhere.
At the senior IC level
Now you’re optimizing for scope and influence, not just a different codebase.
High-leverage moves:
Cross-functional project lead
Take on a project that spans engineering, product, design, maybe even marketing or operations.
This builds your ability to coordinate across disciplines, which is critical for Staff+ and future leaders.
Platform owner
Volunteer to own a platform or internal product (e.g., CI/CD, feature flags, developer portal).
You become the person who makes other teams work faster and more safely, which is hard to cut.
Principal-style work
Even without the title, look for chances to set standards, lead migrations, or steward a technical strategy across teams.
These experiences are exactly what senior hiring managers look for when filling Staff or Director-adjacent roles.
At the manager level
Mobility at this stage is about handling a broader scope and more ambiguity.
Take responsibility for an initiative spanning several squads or domains (e.g., a reliability push, security remediation, or large migration).
You learn how to orchestrate many moving parts under a single goal.
Cross-org programs
Work on something that touches multiple departments; for example, a billing overhaul with finance, or a data program with marketing and compliance.
This gives you the language and relationships you need for Director/VP-level roles.
In each case, the pattern is the same: you’re looking for rotations that expand the number of places where your experience is obviously relevant.
How to pitch and land a rotation without burning bridges?
Rotations work best when they’re a win for you, your manager, and the business. The quickest way to make them contentious is to frame them as “I’m bored; get me out of here.”
A better approach:
Start from a business need
Identify a problem the company cares about: reliability, platform cost, developer productivity, a new product line, or compliance.
Show how a rotation would put you closer to solving that problem.
This makes it easier for your current team to adjust.
Come up with a succession plan
Be explicit about how your current responsibilities will be covered.
Suggest people who could take over and how you’ll help them ramp.
Frame it as growth that benefits the org
“If I spend 6–12 months in platform/security/data, I can bring that knowledge back into our product area and help us move faster and safer.”
For managers: “Leading this cross-team initiative will make me more effective when I come back to own a larger part of the org.”
Ask for a clear timeframe and expectations
Agree on duration (e.g., 6–12 months) and what “success” looks like.
This reassures your current manager you’re not disappearing forever, and gives everyone a point to review.
Handled well, a rotation is not “abandoning your team;” it’s investing in skills and context that make you more valuable to your current company and any future one.
When the market turns, or your org changes shape, those extra dimensions in your experience are often the difference between “I’m stuck” and “I have three realistic options I can take next.”
Step 5: Build Your Sponsor Bench and Network
Skills and impact matter, but when things get messy – re-orgs, layoffs, surprise opportunities – who knows you can matter just as much as what you can do.
That’s where mentors, sponsors, and your wider network come in.
Mentors vs Sponsors (and why sponsors matter more in layoffs)
We often blur these two, but they play very different roles.
Mentors:
Give you advice and perspective
Help you think through decisions
Share their own experience and mistakes
Sure, they’re essential for growth, but in a layoff, a mentor might say, “I’m so sorry, let me know how I can help.”
Sponsors are different:
They put your name forward for roles, projects, and promotions
They vouch for you when you’re not in the room
They can sometimes pull you into a new role when your old one disappears
In a restructuring or layoff scenario, a sponsor is more likely to say:
“We need to make sure we keep Alex. If this team goes away, I want Alex over here with me.”
You don’t need dozens of sponsors. Two or three people with real influence who know your work and trust you can change the trajectory of your career.
How to Become “Sponsor-Worthy”
You can’t just walk up to someone senior and ask, “Will you sponsor me?” Sponsorship is usually the result of how you show up, not a formal arrangement.
Ways to make yourself sponsor-worthy:
Deliver visible wins that make them look good
Ask yourself: “What does this person care about? What are they on the hook for?”
Then look for ways your work can help them hit those goals.
When you deliver, make sure they’re clearly connected to the success (they backed you, gave you the chance, cleared the path).
Show reliability in high-stakes situations
Take the gnarly project that really matters, not just the shiny one.
Communicate early and often when things go wrong. Just don’t go silent.
Be the person who stays calm, organized, and constructive when everyone else is stressed.
Be easy to advocate for
Keep your “anti-layoff” portfolio up to date so sponsors have concrete stories and metrics to use when talking about you.
Be clear about what you want next (“I’m aiming for Staff” or “I’d like to lead a team”) so they know which doors to open.
Sponsorship tends to follow people who consistently make leaders’ lives easier and results better. If you focus on that, the support often grows naturally.
Network Design for Resilience
Finally, think of your network as career infrastructure: you want both redundancy and reach.
Internal networks
Aim to know – and be known by – people beyond your immediate team:
Product managers and designers
Folks in data, security, and platform/infrastructure
Finance or operations partners you collaborate with
This helps you:
Spot opportunities for rotations and new roles earlier
Get context on what the business actually cares about
Have more people willing to vouch for your impact if things get bumpy
External networks
When your company hits turbulence, it really helps if your world doesn’t end at your corporate email address.
Alumni networks – previous companies, universities, bootcamps. Stay in loose touch; they’re often hiring before the job ad goes public.
Even light-touch connections – a quarterly message, an occasional coffee, sharing something helpful – can make you the person they think of when a role opens up. It is a repeating story we hear in our community.
Over time, you want your network to span:
Multiple companies
Multiple industries
A mix of ICs, managers, and senior leaders
That way, when you need to move, you’re not starting from zero.
And suppose you’re looking for a place where future leaders and current CTOs actually hang out. In that case, that’s exactly the gap the CTO Academy community is designed to fill – a space to learn, compare notes, and build the kind of relationships that make the next move easier when the market shifts.
Step 6: Gen AI and Your Next 5 Years (By Level)
You can’t talk about tech careers in 2025 without talking about GenAI. It’s in every board deck, every strategy memo, every “do more with less” conversation. But the picture on the ground is more nuanced than “AI will take all the jobs” or “AI is just hype.”
The question you actually need to answer is: “How do I use this wave to become more valuable over the next 5 years, not less?”
What’s Actually Happening Now
A few realities to anchor on:
Gen AI is excellent at bounded, language-heavy tasks Writing boilerplate code, tests, docs, emails, fundamental analysis, summaries, etc. The right tools and prompts (specs) can speed that up dramatically.
It is not (yet) replacing whole teams overnight Most organizations are in a mix of “experiments,” “pilot projects,” and “some teams using it heavily, some barely touching it.” There are more headlines than well-run, scaled implementations.
AI shows up in layoff stories, but rarely alone When you read the details, AI is usually part of a broader push: “We’re overstaffed after the pandemic; we need to cut costs, and we’re also restructuring around AI and automation.”
So the risk isn’t just “the AI replaces me”. It’s:
“Teams that know how to use AI well will run leaner and faster. The people who don’t adapt will be the easiest to cut or bypass.”
The flip side is that, used well, AI is one of the fastest ways to build a track record of impact in a short period of time.
What to Do at Each Level
Let’s make this concrete.
Junior: turn AI into your amplifier, not your crutch
Your priorities:
Master AI assistants for coding and docs
Use them daily for scaffolding, tests, refactors, docs, and learning.
Always read and understand the output; don’t become a paste-bot.
Build breadth in “career-safe” foundations
Get comfortable with at least one cloud platform.
Learn the basics of data flows, APIs, and security hygiene.
Understand how your team’s system fits together, not just your ticket.
Own at least one measurable “I reduced toil” story Examples:
“I used an AI tool to generate and improve our tests; flakiness dropped, and we caught more bugs earlier.”
“I automated a boring internal task with a small script + AI, saving the team a few hours every sprint.”
These early stories show you’re not just a consumer of AI but someone who makes the team more effective with it.
Mid/Senior IC: drive AI adoption for your team
You’re now in a position to shape how the people around you work. So your job now is to move from “I use AI” to “I helped the team use AI effectively and safely.”
Drive team-level AI adoption
Evaluate and propose tools that actually help (coding assistants, test generators, doc tools).
Set some light-weight patterns and guardrails: what’s OK, what isn’t, and how to keep quality high.
Run small experiments and share results.
Own a platform or system that multiplies the work of other engineers
Internal tooling, CI/CD, observability, feature flags, data pipelines…
Add AI where it makes sense – log summarization, automatic documentation, test suggestion – and show the difference in throughput or reliability.
This is how you start to look like Staff/Principal material: you’re not only technically strong, you change how entire teams deliver.
Tech Lead/EM/Manager of Managers: make AI part of how your teams operate
At this level, your job isn’t to write the prompts. It’s to ensure AI improves outcomes, not just produces more noise.
Use AI to raise throughput and quality
Encourage teams to identify where AI could reduce cycle time, improve test coverage, or reduce repetitive work.
Support experiments: “For this sprint, we’ll try X and measure Y.”
Run experiments, collect data
Ask: “What did the team do differently? How many hours did we save? What changed in our metrics?”
Capture before/after so this doesn’t stay hand-wavy.
Less manual toil → same output with fewer people or more output with the same people.
When you can say, “We used AI to cut lead time by 30% and reduce incident rates by 20%,” you’re not in the “nice to have” bucket. You’re in the “we need this person shaping our org” bucket.
Director/VP/CTO path: own the AI agenda, not just react to it
At senior levels, Gen AI is less about tools and more about strategy, governance, and economics.
Your responsibilities start to look like:
Own AI strategy, governance, and portfolio
Where do we invest: internal tools, customer-facing products, both?
What are our principles and guardrails around data, privacy, compliance, and quality?
How do we avoid dozens of disconnected AI experiments that never scale?
Manage vendor risk and economics
Understand the total cost of ownership for the AI stack.
Decide when to build, buy, or partner.
Track usage, ROI, and the risk of vendor dependency.
Communicate AI’s impact to the C-suite and board
Translate “we’re using AI” into clear, non-hyped language:
What have we shipped?
What changed in revenue, cost, risk, and speed?
What are the next bets, and what could go wrong?
This is where AI becomes part of the overall technology and business strategy, not a side project.
And if you’re operating at that multi-team or org level – or aiming to – you also need another language: the language of boards, investors, and non-technical executives. How to talk about AI, risk, and investment in a way that lands.
That’s the level our Digital MBA for Technology Leaders is built for: giving you the strategic, financial, and communication toolkit to lead AI-era portfolios confidently, not just survive the next round of buzzwords.
Step 7: Two Layoff-Resilient IT Career Roadmaps
Let’s see all of this in practice.
Bear in mind that these two roadmaps aren’t prescriptions. They show how you might build the three pillars (impact, scarce skills, mobility) over time, and how AI fits in naturally rather than as a bolt-on.
Roadmap A — IC to Engineering Manager (≈3–5 years)
Stage 1: Mid IC → Senior IC
Focus: grow from “good engineer” to “business-aware problem solver.”
Business metrics you start to influence
Delivery speed on your team (cycle time, lead time).
Defect/incident rates for the services you touch.
Gen AI responsibilities
Use AI assistants for your own coding, tests, and docs.
Run small experiments (e.g., AI-generated tests) and share results with the team.
Visibility & network changes
Your manager and tech lead see you as someone who reliably closes the loop.
You start to be invited into slightly earlier stages of planning and design.
Stage 2: Senior IC → Tech Lead
Focus: shift from “I deliver my work” to “I help the team deliver.”
Business metrics you influence
Team throughput (how much gets done, how often).
Quality metrics (incidents, escaped bugs).
Stakeholder satisfaction in your team’s area.
Gen AI responsibilities
Help the team adopt AI-assisted workflows safely (coding, testing, docs).
Identify at least one AI-driven improvement that moves a team metric.
Visibility & network changes
Product managers and other teams know you as the go-to person.
You spend more time in cross-functional meetings (product/design/ops).
You start to build relationships with adjacent teams and their leaders.
Stage 3: Tech Lead → Engineering Manager
Focus: you step into owning people, delivery, and outcomes.
In the next section, we’ll turn this into a decision point, helping you pick the next concrete step and, if it makes sense, the kind of structured support you might want along the way.
Step 8: Choose Your Next Step (and Program Path)
By this point, you should have a rough sense of:
Which lane are you in (IC or leadership)
Where you sit on the roadmaps
Which pillar (impact, skills, mobility) needs attention next
Now it’s decision time: what do you do with that insight?
For most, the next move falls into one of two buckets.
Path A: “I’m 2–7 years into my career; I want to lead my first team or be a stronger tech lead.”
You’re a mid/senior engineer or early tech lead. People already come to you with questions. You might be doing half the job of a manager without the title, or you’re about to make that jump and don’t want to wing it.
Your challenges sound like:
“I’ve never been taught how to run 1:1s, give feedback, or handle performance issues.”
“I need to talk to product and the business in a way that actually lands.”
“I’m worried about becoming ‘just another middle manager’ in a flattening org.”
For you, the focus should be on foundational leadership:
Leading humans, not just tickets.
Communicating clearly up, down, and sideways.
Understanding the basics of finance and business trade-offs.
Running a team with absolute ownership in a world that expects more impact from fewer layers.
Path B: “I already lead teams or managers; I need to think like an executive.”
You’re an Engineering Manager, Head of Engineering, Director, or similar. You’re already responsible for people and outcomes. The question isn’t “Can I lead a team?” anymore; it’s:
“How do I operate at the Director/VP/CTO level?”
“How do I make smart calls on AI, architecture, and investment, not just delivery?”
“How do I talk to the C-suite and board in their language?”
Your next edge comes from thinking and operating like an executive:
Strategy and portfolio design in the AI era.
Finance and economics – margins, runway, unit economics, investment decisions.
Governance and risk – especially around data and AI.
Organizational design – how to structure teams and spans in a flatter world.
Board-level communication – clear, concise, credible.
That’s where the Digital MBA for Technology Leaders comes in – a structured way to build the strategic, financial, and organizational toolkit that sits on top of your existing tech and people skills so that you can lead whole portfolios and organizations, not just teams.
Look back at where you are on the roadmaps, be honest about your current challenges, and then pick one:
Future Leaders, if you’re preparing to lead people and deliver for the first time (or want to feel solid in that seat finally).Learn more about the course here.
Digital MBA for Technology Leaders if you’re already running teams or managers and want to step into the kind of leadership that still matters when org charts flatten, and AI reshapes how work gets done. Learn more about the program here.
FAQs (Layoffs, GenAI, and Path Choices)
Are today’s tech layoffs mainly because of AI?
No. AI appears in some announcements, but most layoffs are still driven by a mix of post-COVID overhiring, cost-cutting, and restructuring. AI is usually part of a wider “do more with less” story, not the sole reason people are let go.
Is the IC track or the management track safer now?
Neither track is automatically safe. Middle management layers are being squeezed, and low-impact IC roles are easy to cut, too. The safer place is wherever you can clearly show business impact, own critical systems, or lead AI-augmented teams that the company genuinely relies on.
How do I stay layoff-resilient as a junior developer?
Stop thinking of yourself as “ticket taker #27” as fast as possible. Use AI tools to work faster and learn faster, build breadth (cloud, data, security basics), and take ownership of a small system or internal tool. Aim for at least one clear “I reduced toil/improved a metric” story each year.
How do I use Gen AI at work without becoming replaceable?
Use Gen AI to remove low-value work, not to switch your brain off. Focus on automating boilerplate, tests, docs, and repetitive tasks, then use the time you gain to work on architecture, reliability, alignment with business goals, and helping others use AI safely. People who can design and govern AI-driven workflows are much harder to replace than people who just paste model output into the codebase.
How long does it realistically take to become a CTO?
There’s no single timeline, but for most people it’s a 10–15-year journey from first engineering role to credible CTO in a serious organization. Some get there faster in startups, some take longer. What matters more than years is the scope you’ve owned (teams, products, P&L), the problems you’ve solved, and how well you can operate with executives, boards, and investors.
Can I still switch into IT now, or is it “too late” because of AI?
It’s not too late, but it is more selective. Entry-level roles are tighter than they were a few years ago, and AI has raised the bar on what “junior” looks like. If you’re switching in, aim straight for in-demand areas (cloud, data, security, platform) and show that you can use AI productively, not that you expect it to do your job for you.
Tools & Resources for Designing Your IT Career Map
You don’t have to design this in a blank Notion page.
Here are a few CTO Academy resources you can plug straight into what you’ve just read:
Skills Assessment – find your current gap profile Get a clear view of where you’re strong, where you’re light, and how that maps to the next roles on your roadmap. Use it to prioritise which pillar to work on first: impact, skills, or mobility. Start your skills assessment.
“90 Practical Tips for Tech Leaders” – your playbook for next steps Short, practical ideas you can actually try in the next sprint, quarter, or performance cycle. Ideal if you want to turn this article into specific habits rather than a nice theory you forget next week. Get your free copy here.
CTO Salary Calculator & compensation content – reality-check by level Sense-check what people at your level (and the next rung up) are earning in different regions and company types. Useful both for negotiating where you are and for picking the kind of roles that actually move the needle. Compare salaries here.
Key articles for aspiring and current technology leaders
CTO network/community pieces – to understand how other leaders are navigating the same market shifts.
Pick one tool to start with – assessment, eBook, salary check, or a deep-dive article – and use it to firm up your map into something you can act on over the next 3–12 months.
Conclusion
Your Career Path Is a Design Problem, Not a Lottery
You can’t control interest rates, market cycles, or whether your company decides to flatten another layer of management.
What you can control is how well-designed your career is.
Designed careers have three things in common:
They’re relevant to the business It’s obvious how you make or save money, reduce risk, or speed things up.
They’re hard to replace You sit at the intersection of scarce skills – systems, data, security, AI, leadership – not just “generic engineer #47.”
They’re able to move You’ve built enough breadth and network that you can pivot between teams, domains, and companies when you need to.
That’s what you’re really aiming for: not just a nicer job title, but a profile that companies fight to keep.
So before this just becomes another article you scroll past, pick one concrete step for this week:
Map your next two roles – based on your lane, write down the next 2–3 realistic titles and what they actually require.
Choose one pillar to strengthen first – impact, skills, or mobility. Don’t try to fix everything at once.
If you’re ready for structured support, pick your path:
Future Leaders Course if you’re 2–7 years in and gearing up to lead people and delivery for the first time. Learn more
Digital MBA for Technology Leaders if you’re already leading teams or managers and want to operate like a VP/CTO in the AI era. Learn more
The market will keep changing. The question is whether you let it throw you around, or use it as the backdrop for a career you’ve actually designed.
Every week, CTO Academy hosts live sessions and debates with seasoned technology leaders and career coaches. Members can ask questions and get immediate answers from experts. Last month, one of our sessions looked at the major shift in tech job market trends. Our guests, CTO Sean Handley, founder of London CTOs Barry Cranford, and career coach Adam Horner, explained what has changed and how to adapt to the new reality.
Table of Contents
Get the IT Career Path Roadmap (Free PDF)
Want more than scattered ideas? Get our IT Career Path Roadmap PDF – an 8-step framework to map your next roles, sharpen your skills, and build a layoff-resilient tech leadership career. Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
Here’s the bitter reality in a nutshell: the job market for technology leadership roles has tilted significantly in the last 18 months. By some accounts, it has been the worst job market in the last three decades. However, on closer look, the situation is not nearly as bad as it appears at first. You’ll understand why shortly.
First things first:
What’s Really Happening With the Job Market?
Long story short, major layoffs in tech companies, triggered by the increased cost of money, consequently led to (seemingly) decreased demand for leadership roles.
For years, new tech companies were popping out all over the place. However, rising costs, reduced profits, and the cost of debt ultimately forced these companies to downsize and consequently flood the job market with tech professionals.
Even tech startups, once the sponges of massive employment of software engineers and technology leaders, are now bootstrapping or hovering in the stealth mode for a lot longer than they used to. Many have run out of money and shut down their operations because VCs are becoming more cautious.
Historically, the Tao of tech startups was to hire en masse and figure out the monetization later. What made that possible was the more than generous funding. However, with VCs pulling the brakes on their once wild chase for the next tech unicorn, fewer of these startups can survive.
According to some, all of this has caused less demand for senior technology leadership roles. Teams are getting leaner, including SLTs, even though the complexity in most companies remains relatively unchanged.
However, the reality is different.
We did a fresh job market research and ran a historical analysis to see if anything changed in the last 12 months. The data indicates divergent trends between the US and UK CTO job markets over the past 6-12 months. The UK shows a clear decrease in the absolute number of available CTO positions but with significantly increased compensation, suggesting companies may be consolidating these roles while placing higher value on them. The US market, on the other hand, maintains a high volume of positions across platforms.
So the demand is still here, at least in the US. Which means that the problem lies elsewhere.
But before we unveil the real issue, we cannot bypass the elephant in the room, Gen AI.
No matter how hard the tech community is pressing against the ability of AI to produce working code, nobody can dispute the fact that AI-assisted programming has enabled companies to drastically downsize their teams. Most notable examples include Spotify, Klarna, and Amazon, especially for code migrations.
Sean Handley, who wrote a blog about his experience with job hunting after being laid off in December 2024, said this on the subject: “There is something I didn’t put in the article, which I was kind of loath to put. In pretty much every process where I spoke to a human, they wanted to talk about Gen AI stuff. There were always questions about how do I use Gen AI, what its value is, what the pros and cons are, and what the risks are. Then, it would get more personal, like how am I using it personally, or how are my teams using it? That’s definitely been the thing that’s sort of been seismically changing what it means to work in tech. And to be honest, that’s been one of the most frightening things. I mean, it’s like I’ve spent almost 20 years getting myself to a point where I feel like I’m good at something, and suddenly all the rules have changed.”
The bottom line is simple: fewer people means reduced necessity for leadership, which translates to fewer universal CTO roles.
Which brings us to the new reality of a CTO role and the real reason why some former technology leaders are now on the job market.
Stratification of a CTO Role
Let’s not forget that the CTO position is relatively new. It’s been around since the late 80s, and, in the past, experience in technology and Ivy League education were the two major qualifications to get a job.
Lately, however, executive teams are looking to hire the right kind of CTO instead of a general expert. That is, they are looking for specific subject matter expertise. And this shift occurred only recently, some 12 to 18 months ago. For example, you will now often see that a company is looking for a Field CTO rather than a general Chief Technology Officer because the role demands active client engagement, which was unheard of in the past. Historically, CTOs were invisible to the customer’s eye. Today, however, they are often at the forefront of the sales strategy as the product’s evangelists, especially in B2B sales.
Necessary Career Adjustments
According to Adam Horner, and as it’s been implied throughout Sean’s blog post, the difference between success and failure in job applications is now in optimal and clear positioning.
What is optimal and clear positioning?
Ask yourself this:
What is my background?
What kinds of problems can I solve for organizations?
This is the value you are bringing to the company that makes it unique and specific. It can be industry expertise, sector expertise, or solving ad hoc problems the company is currently facing (e.g., migrating a monolith). Whatever it is, those specific skills, backgrounds, and experiences set the foundation for positioning.
In other words, should you ditch the broad networking/broadcasting strategy and attempt to build a niche-level authority position?
The short answer is yes because, in the past, you could simply just be a CTO; however, that doesn’t cut it anymore. Today, you must be area-specific (i.e., cloud integration is my area of expertise, and I reign supreme in it).
There are more CTO roles now than it was before. These roles are distinct and verticalized because technology has become a basic requisite for ANY company or organization. You just need to define where exactly you fit in, in what we can now call the spectrum of a CTO role.
But what if you are a generalist?
How To Position Yourself If You Are a Generalist?
You’ve kind of done a little bit of everything. You’ve been in tech for two decades, coming in through program management and not necessarily as a developer. Nonetheless, you managed to work your way up to a CIO role where you were responsible for cloud infrastructure, engineering, and cybersecurity. You also worked in product development and customer success. Basically, you are not exactly a hands-on engineer. So, how do you differentiate yourself?
The general advice from Adam Horner is this: pick something. In other words, pick your favorite thing that can make the biggest difference out there. Focus everything around that one thing with a recent track record and sell yourself based on that.
Once you get to the point of the interview where you can say, “I can solve this problem. I’m good at this problem. I’ve faced it before and I can solve it this way,” the follow-up questions will start coming, “Oh, can you also solve this? Can you solve that?”. That’s when your generalism comes to the fore.
Therefore, lead with your specialization, but always remember that your generalism is an added value because you know how elements fit together: from product development via data analytics and finances to customer success. And that’s the bit that’s likely to put you in front of the competition.
The Critical Skill Many Tech Professionals Are Missing
In the not-so-distant past, technical expertise was enough to get you a senior tech leadership role. Today, on the other hand, you must possess a clear understanding of where and how exactly the technology adds business value as well. Which means that, besides practical coding, technology management, and team leading experience, you need to have strong business acumen. Without it, it is going to be close to impossible to design and align technology strategy with the company’s business goals and know when to pivot. To put it bluntly, the days of CTOs hovering above their engineering teams and being clueless about what’s going on outside their bubble are long gone.
This is the reason why modern technology leadership programs place much focus on business-related modules instead of just teaching team leadership and technology management. Because, in the end, it’s rarely about the tech. It’s more about running a successful business, and that implies nuanced knowledge of how businesses operate in different market conditions.
To give you an example of such a curriculum, we’ll take a brief look at the lectures in the Digital MBA for Technology Leaders that are relevant to our topic.
Out of nine modules, three are focused solely on business fundamentals, finances, funding, and aligning technology strategy with business goals. We are talking about 75 dedicated lectures that cover every single aspect of business operations from a non-technical perspective.
These lectures build the critical knowledge required to execute your responsibilities as a modern-day (even area-specific) Chief Technology Officer. Without it, even if you are in a tech leadership role at the moment, you might soon find yourself stepping back to hands-on engineering rather than leading teams because you are missing a fundamental understanding of the convergence of technology and business.
As a rule of thumb, these programs include memberships and alumni access that is arguably the single most important asset in your arsenal when seeking a better or new job.
The Power of Networking
Barry Cranford, the founder of London CTOs, told an interesting story. Earlier that day, when we were hosting this particular live session, Barry had lunch with a fellow CTO who recently started a Fractional CTO role after spending four months hunting for jobs. At one point, he almost gave up because he felt like he was trying too hard. He was pushing himself on LinkedIn and applying for too many jobs, but not getting anywhere. Until the guy he got drunk together at the conference in Barcelona seven years ago, noticed one of his LinkedIn posts and sent him a message that led to his current job.
This is the story that repeats itself over and over again: a network eventually comes through.
How to find and navigate the ideal community of technology leaders?
We hear it from our members all the time. They get hired thanks to the push from the people they worked for or communicated with. And more often than not, it has nothing to do with the actual job application, but with peer-to-peer networking.
So instead of relying on your LinkedIn CV as the first impression, get into the community and connect with people.
When you first meet someone, don’t immediately tell them that you’re looking for work. — Barry Cranford, London CTOs
As Sean himself admitted, “At first, it was emotionally difficult. Rejections and ghosting get to you. But after reaching out to other people whom I knew were job seeking and just checking in with each other, you start to feel a certain ease because you are not alone. There is a bit of camaraderie there that is genuinely super helpful, which makes other conversations easier because you are not approaching it from a negative standpoint anymore.”
Be very mindful about your social posts. As the final stage of the hiring process, the recruiter is more focused on the negative stuff; for example, a post in which you vividly describe your discontent with the job market and recruiters. Even if the interview has gone well, this textual relief valve you used to make yourself feel better will most likely result in ghosting.
Another interesting angle to the whole networking strategy is attending non-technological events or events in different industries.
People talk about their problems; it’s inevitable in these types of gatherings. Often, they don’t realize that someone with a background in technology can solve some of those problems. So, from just another attendee, you turn into an asset or a magic bullet, if you will.
As one of our members said, “Tech events are saturated with all the same people that are competing for the same thing within the realm of the same mental space.” In non-tech events, on the other hand, you might be the only “IT guy,” remember that.
In one of our most recent online sessions, we discussed the troubling trends in the tech job market, especially in the technology leadership category (e.g., CTO, fCTO, Head of IT, etc.). In some instances, it can take up to 18 months to land the executive role. While the shifts in the market are partially responsible, your CTO resume might also be the cause for such a dramatic lag or inability to even land an interview. Paradoxically, it is that same resume that unlocks the door and lets you in.
Therefore, in this guide, we walk through the essential elements of every CV and explain the capital rule of job applications, regardless of the role’s seniority or even the type of job, industry, niche, or organization. We also use the most recent CTO job ad from Glassdoor to better explain the optimal resume strategy. So, to avoid the frustrations caused by repeated rejections or ghosting and a lengthy application process like Sean Handley experienced, this is the one CV guide you should carefully review.
Table of Contents
Get the IT Career Path Roadmap (Free PDF)
Want more than scattered ideas? Get our IT Career Path Roadmap PDF – an 8-step framework to map your next roles, sharpen your skills, and build a layoff-resilient tech leadership career. Fill in the form and we’ll send you the PDF version so you can download it, annotate it, and use it as a living plan for your next career moves.
The two parts of the CV, the cover letter and resume, aren’t about you; they are about the organization and the role you are applying for.
This may sound a bit contradictory because we all like to think that the purpose of a good resume is to reflect all our amazing skills and accomplishments.
Well, that’s only partially true, as certain specific experiences may be irrelevant—or even detrimental. That is, listing them takes attention away from what a potential employer is mostly interested in.
Now, let’s explain what this means in practice. We’ll start with the basics: the key elements of every resume.
What Are the Key Elements to Include In a CTO Resume?
There are six key elements you must include in a CV. In their correct order, they are:
Cover Letter
Portfolio
Work experience
Skills
Personal Information
Education
Work experience is merely listing all the roles and the companies you worked for. Portfolio, on the other hand, is that one true asset that ticks just the right boxes. Sure, you can use them interchangeably, but…
Ask yourself an inevitable question: What separates you from 50 to 60 other candidates applying for that same job?
Think about it. You all have a university education, 10+ years of work experience in the private and public sectors, and experience in leading cross-functional teams and building solutions. So why would they hire you instead of any of them?
It comes down to two things: a cover letter and a portfolio.
These two are used complementarily to a) address the problem that made the employer search for the new employee in the first place, and b) prove the undeniable expertise in the matter.
Many falsely believe that a portfolio is only used by those building products and services. For all intents and purposes, an example of successful completion of the digital transformation process in Company A and the successful migration of the on-prem, monolithic system to the cloud infrastructure in Company B are, in fact, portfolio samples that can land a job in Company C. You only need to emphasize them in your cover letter.
Which leads us to the most common mistakes people make when applying for jobs.
Common Mistakes to Avoid When Writing a CTO Resume
There are two capital mistakes you want to avoid at all costs, especially if you are a serial applicant (i.e., using templates to apply to as many jobs as possible in the shortest time due to growing frustration):
Impatience
Suboptimal prioritization
#1 causes #2, leading to a junk CV and continuous frustration. Remember that.
Before applying for a job, you must determine why that organization is even looking for a candidate for that particular role. In other words, you must do your due diligence and research the organization from every possible angle. Without this investigation, you can’t prioritize skills and portfolio samples that will enable you to stand out from the crowd.
(We call it samples because they are fragments of the overall role you played in an organization, the scope of which most likely far exceeded just that specific part.)
How Do You Do It?
(Especially if the company outsourced the hiring task and you don’t know the company’s name.)
According to the outsourcing company, the employer is a “technology-driven organisation that utilises advanced data processing and modelling techniques to develop industry-leading solutions. Operating in a competitive sector, they focus on creating innovative and scalable systems that drive impactful decision-making.” In other words, they are building analytical and monitoring tools with different tiers to expand the market reach.
The list of responsibilities is generic; something you commonly see in these types of job ads. But when you scroll down, you find the real juice: Essential & Desirable Skills and Experience, where a few requirements simply stick out:
Experience working in data-intensive environments.
Familiarity with Python or similar programming languages.
Exposure to algorithmic modelling, analytics, or data-driven applications.
Prior experience in industries that leverage complex data environments.
It’s here where you can see their problem and the driving factor behind the decision to hire a (new) CTO. And in this particular case, it is these four requirements that you must address in your cover letter and then back them up with portfolio samples.
For example, experience with Python indicates that they are looking for someone with a strong technical background. Algorithmic modelling and complex data environments most likely mean that the ideal candidate possesses hands-on experience with AI-powered analytical and decision-making enterprise-level solutions. That’s why they are looking for someone who already knows how to leverage complex data.
Therefore, you need to prepare three distinct portfolio samples that, ideally, complement each other: programming, modelling, and data management.
One remark here, though: if it’s not Python, then make sure the algorithmic modelling is closely related to the type of solution they are looking for, because they have clearly emphasized that specific programming language, which means that their teams are using it. In other words, if you lack one, compensate with the other.
Think of those portfolio samples contextually in your cover letter and blend them in to strengthen every statement. That is, answer each of these “questions” with the actual successful examples of your past work, relevant to the exact requirement. Do it right, and nobody will even read the next page of your CV, but simply schedule an interview.
In case you do not have a relevant portfolio sample, you are not 100% qualified for the job, regardless of your years of experience and education.
As you can see, running specific job requirements against your portfolio gives you an immediate clue about your eligibility. It saves time and nerves if you are applying for multiple jobs. Use your portfolio to filter out or, at the very least, prioritize applications.
If the company is looking for a CTO with experience in building an X type of solution, find a similar product you worked on in your past and wave it in front of their eyes. Make it the center of your cover letter.
Finally, when listing your skills, follow the exact order the employer used in the job ad. In other words, simply reiterate with a bit of different wording.
Now, you might be wondering about this specific format of a resume with the focus on the cover letter and portfolio, but when you are competing for a job in a fearsome competition, you want to attack with the tip of your spear and not the edge of your shield.
So…
What Is the Ideal Format of a CTO Resume?
The order of CV elements in traditional templates starts with a photo, basic personal data, education, skills, and work experience. By default, they all include a cover letter, which most disregard, ignore, or fail to write optimally.
This might sound controversial, but such an order is not aligned with the employer’s interests. They (employers) primarily want to know two things:
Can you solve their problem? (CV element: Cover Letter)
What makes you so sure? – (CV element: Portfolio Sample)
Only if these two answers satisfy them, they’ll move to your name and that lovely filtered photo of you in the suite.
I’m convinced that a huge amount of candidates are rejected simply because the hiring team didn’t have a strong enough signal from the hiring process. — Sean Handley, CTO
So, if you imagine a pile of 60+ resumes on someone’s desk, which one would you say will attract immediate attention:
The one that opens with the solution to their problems or the one with the photo, name, and address?
In case you don’t have a referral with the power to put your CV directly into the hands of the decision maker, your cover letter is the only thing that can potentially put you at the top of that pile.
As Adam Horner, Berry Cranford, and Sean Handley repeatedly stated during the session, your best chance of landing a job quickly and with minimum effort is through a referral. And that’s where a global community of technology leaders supporting each other and frequently posting jobs in dedicated channels comes in extremely handy.
Therefore, if you don’t have a network, your only asset is a fine-tuned resume.

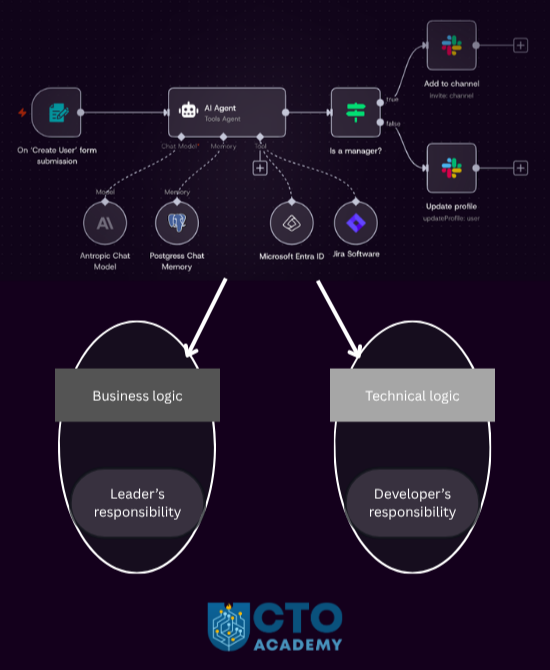





")

")
")



")

")

